
参考文档:Sharding-Jdbc实现读写分离、分库分表,妙!
1. binlog
binlog(归档日志)
MySQL 整体来看就有两块:一块是 Server 层,主要做的是 MySQL 功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,称为 binlog。
binlog 记录了对 MySQL 数据库执行更改的所有操作,不包括 SELECT 和 SHOW 这类操作,主要作用是用于数据库的主从复制及数据的增量恢复。
使用 mysqldump 备份时,只是对一段时间的数据进行全备,但是如果备份后突然发现数据库服务器故障,这个时候就要用到 binlog 的日志了。
binlog 格式有三种:STATEMENT,ROW,MIXED
- STATEMENT 模式:binlog 里面记录的就是 SQL 语句的原文。优点是并不需要记录每一行的数据变化,减少了 binlog 日志量,节约 IO,提高性能。缺点是在某些情况下会导致 master-slave 中的数据不一致。
- ROW 模式:不记录每条 SQL 语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了,解决了 STATEMENT 模式下出现 master-slave 中的数据不一致。缺点是会产生大量的日志,尤其是 alter table 的时候会让日志暴涨。
- MIXED 模式:以上两种模式的混合使用,一般的复制使用 STATEMENT 模式保存 binlog,对于 STATEMENT 模式无法复制的操作使用 ROW 模式保存 binlog,MySQL 会根据执行的 SQL 语句选择日志保存方式,mysql 默认这种方式。
statement 模式的弊端
当我们使用 mysql 函数,比如 now() 获取时间的时候,记录此语句,主从复制时,在另外一个数据库执行会导致两个库的数据不一致。
2. redo log
先回顾下事务的持久性:当事务提交或回滚后,数据库会持久化的保存数据。
redo log 的作用:确保事务的持久性。以防在发生故障的时间点,还有脏页未写入磁盘,在重启 mysql 的时候,根据 redo log 进行重做,从而达到事务的持久性这一特性。
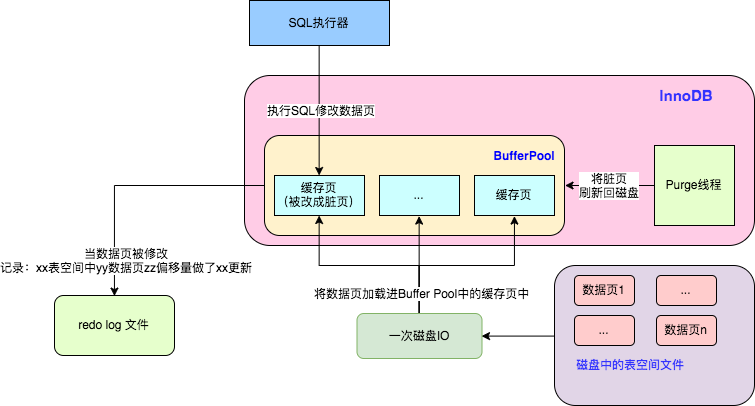
磁盘上的数据文件叫表空间文件,表空间有挺多的,比如系统表空间、undo log 表空间、你也可以让 create 出来的每张 table 都有自己单独的表空间。总之 MySQL 会将表空间数据页通过磁盘 IO 加载进缓存页中。
SQL 执行器会执行你发送给 MySQL 的 SQL 语句,MySQL 为了提高的性能,对于增、删、改这种操作都是在内存中完成的,所谓的内存就是上图中 BufferPool。比如上图中的 SQL 执行器执行了一条 update xxx where id = 1 语句,然后这个 id = 1 数据行所在的数据页就会被你修改成脏数据页。
此外 MySQL 还有专门的后台线程等其他机制负责将脏数据页刷新同步回磁盘。
你可以结合上图然后想一下:万一脏页还没来得及刷新到磁盘中,MySQL 就挂了,怎么办呢?
对于业务代码来说,方才执行的事务是 OK 的,甚至前端都接受到了请求成功的响应。那结果修改的数据没同步回磁盘,MySQL 宕机了会不会导致真实数据和逻辑上的数据不一致呢?
其实不会的!
MySQL 使用 redo log 解决了这个问题,redo 故名思义:重做。
当发生事务(增、删、改)时会导致缓存页变成脏页,于此同时 MySQL 会将事务涉及到的:对 XXX表空间中的XXX数据页XXX偏移量的地方做了XXX更新。
所以 MySQL 意外宕机重启也没关系。只要在重启时解析 redo log 中的事务然后重放一遍。将 Buffer Pool 中的缓存页重做成脏页。后续再在合适的时机将该脏页刷入磁盘即可。
于是对于业务方来说,everything is ok!
redo log侧重于重做!redo log中记录的是物理层面的数据页、偏移量。应对的问题是:MySQL异常宕机后,如何将没来得及提交的事物数据重做出来。
而后面文章中和大家分享的bin log中记录了你对XXX表条件为XXX处的数据作了什么修改,这是些都是逻辑上的概念。
InnoDB 首先将 redo log 放入到 redo log buffer,然后按一定频率将其刷新到 redo log file
下列三种情况下会将 redo log buffer 刷新到 redo log file:
- Master Thread 每一秒将 redo log buffer 刷新到 redo log file
- 每个事务提交时会将 redo log buffer 刷新到 redo log file
- 当 redo log 缓冲池剩余空间小于1/2时,会将 redo log buffer 刷新到 redo log file
MySQL 里常说的 WAL 技术,全称是 Write Ahead Log,即当事务提交时,先写 redo log,再修改页。也就是说,当有一条记录需要更新的时候,InnoDB 会先把记录写到 redo log 里面,并更新 Buffer Pool 的 page,这个时候更新操作就算完成了
Buffer Pool 是物理页的缓存,对 InnoDB 的任何修改操作都会首先在 Buffer Pool 的 page 上进行,然后这样的页将被标记为脏页并被放到专门的 Flush List 上,后续将由专门的刷脏线程阶段性的将这些页面写入磁盘
InnoDB 的 redo log 是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,循环使用,从头开始写,写到末尾就又回到开头循环写(顺序写,节省了随机写磁盘的IO消耗)
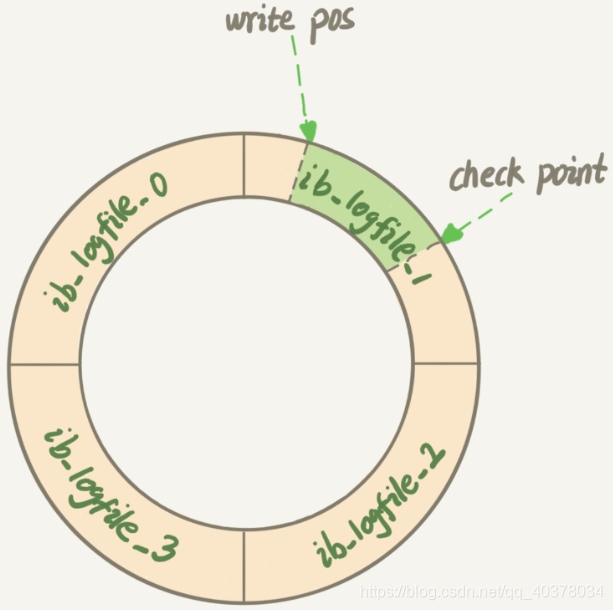
Write Pos 是当前记录的位置,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。Check Point是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
Write Pos和Check Point 之间空着的部分,可以用来记录新的操作。如果 Write Pos 追上 Check Point,这时候不能再执行新的更新,需要停下来擦掉一些记录,把 Check Point 推进一下
当数据库发生宕机时,数据库不需要重做所有的日志,因为 Check Point 之前的页都已经刷新回磁盘,只需对 Check Point 后的 redo log 进行恢复,从而缩短了恢复的时间
当缓冲池不够用时,根据 LRU 算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行 Check Point,将脏页刷新回磁盘
3. 总结
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用
- redo log 是物理日志,记录的是在某个数据也上做了什么修改;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如给 ID=2 这一行的 c 字段加 1
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的,binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志
我们举个例子
create table T(ID int primary key, c int);
update T set c=c+1 where ID=2;
执行器和 InnoDB 引擎在执行这个 update 语句时的内部流程:
- 执行器先找到引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据也本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回
- 执行器拿到引擎给的行数据,把这个值加上1,得到新的一行数据,再调用引擎接口写入这行新数据
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交状态,更新完成
update 语句的执行流程图如下,图中浅色框表示在 InnoDB 内部执行的,深色框表示是在执行器中执行的
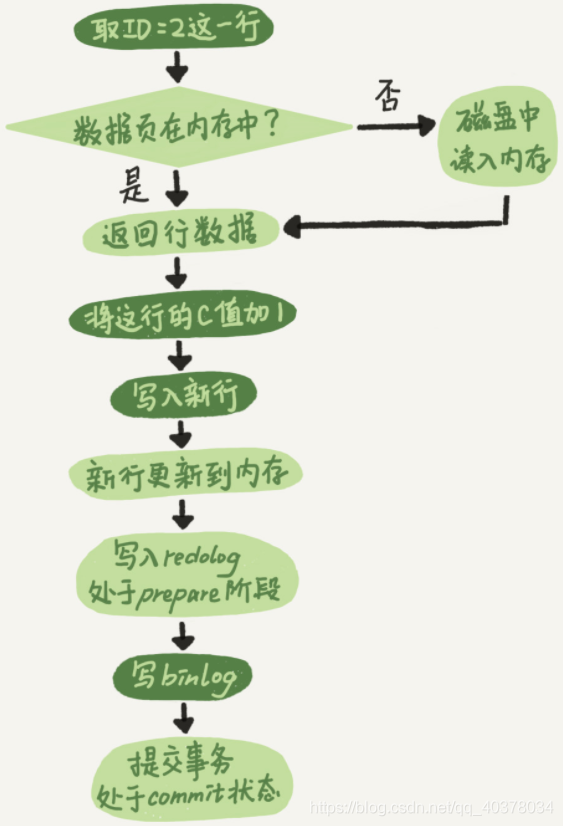
将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是两阶段提交。