
1. Oracle 体系结构
Oracle 的概念和别的数据库不太一样,详细介绍下。
1.1 数据库
Oracle 数据库是数据的物理存储。这就包括(数据文件 ORA 或者 DBF、控制文件、联机日志、参数文件。其实 Oracle 数据库的概念和其它数据库不一样,这里的数据库是一个操作系统,只有一个库。可以看作是 Oracle 就只有一个大数据库。数据库是一个比较偏向于硬件的概念。
1.2 实例
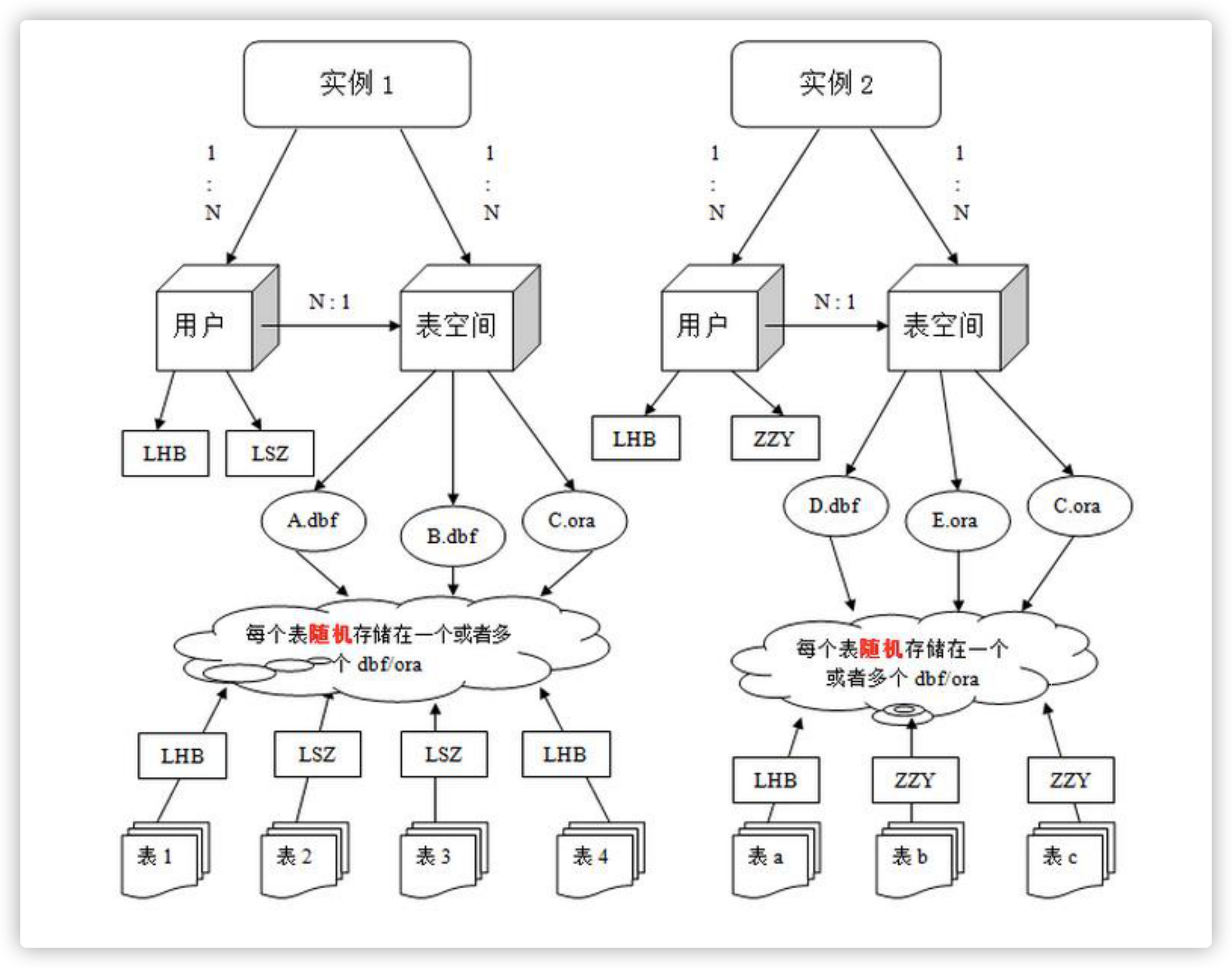
一个 Oracle 实例 (Oracle Instance) 有一系列的后台进程 (Backguound Processes) 和内存结构 (Memory Structures) 组成。一个数据库可以有 n 个实例。实例和数据库概念相似,只是一个偏向于软件的单位。一个数据库可以有多个实例,但一般只有一个。
1.3 用户
用户是在实例下建立的。不同实例可以建相同名字的用户。
在 Oracle 中,管理表的基本单位不是数据库,而是用户,每个用户下面可以都多张表。
不能说某个数据库下面有几张表,而应该是某个用户下面有几张表。
1.4 表空间
表空间是 Oracle 对物理数据库上相关数据文件(ORA 或者 DBF 文件)的逻辑映射。一个数据库在逻辑上被划分成一到若干个表空间,每个表空间包含了在逻辑上相关联的一组结构。每个数据库至少有一个表空间 (称之为 system 表空间)。(当数据文件过多时,会划分为多个表空间)
每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件 (datafile)。一个数据文件只能属于一个表空间。
1.5 数据文件
数据文件是数据库的物理存储单位。数据库的数据是存储在表空间中的,真正是在某一个或者多个数据文件中。而一个表空间可以由一个或多个数据文件组成,一个数据文件只能属于一个表空间。一旦数据文件被加入到某个表空间后,就不能删除这个文件,如果要删除某个数据文件,只能删除其所属于的表空间才行。
表的数据,是有用户放入某一个表空间的,而这个表空间会随机把这些表数据放到一个或者多个数据文件中。
由于 oracle 的数据库不是普通的概念,oracle 是由用户和表空间对数据进行管理和存放的。但是表不是由表空间去查询的,而是由用户去查的。因为不同用户可以在同一个表空间建立同一个名字的表!这里区分就是用户了!
{kind=link}
2. Oracle 基本操作
--创建表空间
create tablespace itheima --表空间名
datafile 'c:\itheima.dbf' --数据文件
size 100m --表空间初始大小
autoextend on --存满时,自动增长
next 10m; --自动增长大小
--删除表空间
drop tablespace itheima;
--创建用户
create user itheima --用户名
identified by itheima --密码
default tablespace itheima;--指定用户的表空间
--给用户授权
--oracle数据库中常用角色
connect --连接角色,基本角色
resource --开发者角色
dba --超级管理员角色
--给itheima用户授予dba角色
grant dba to itheima;
3. sql
3.1 分页查询
Oracle 分页查询中有个 rownum 字段,表示行号,在每个表中出现。
每查询出一行记录,就会在该行上加上一个行号,行号从1开始,依次递增,不能跳着走。
----排序操作会影响rownum的顺序
select rownum, e.* from emp e order by e.sal desc --会看到 rownum 是乱序的
----如果涉及到排序,但是还要使用 rownum 的话,我们可以再次嵌套查询。
select rownum, t.* from(
select rownum, e.* from emp e order by e.sal desc) t;
----emp 表工资倒叙排列后,每页五条记录,查询第二页。
----rownum 行号不能写上大于一个正数。因为 rownum 是从 1 开始连续的
select rownum rn, tt.* from(
select * from emp order by sal desc
) tt where rownum<11 and rownnum>5
--所以我们再嵌套一层
select * from(
select rownum rn, tt.* from(
select * from emp order by sal desc
) tt where rownum<11
) where rn>5
4. 视图
视图就是封装了一条复杂查询的语句。
语法:CREATE VIEW 视图名称 AS 子查询 [WITH READ ONLY]
create view empvd as select * from emp
修改视图会修改原表数据
视图的作用?
- 视图可以屏蔽掉一些敏感字段
- 保证总部和分部数据及时统一
5. 索引
概念:索引就是在表的列上构建一个二叉树,达到大幅度提高查询效率的目的,但是索引会影响增删改的效率。
索引分为单列索引和复合 (多列) 索引
---单列索引
---创建单列索引
create index idx_ename on emp(ename);
---单列索引触发规则,条件必须是索引列中的原始值。
---单行函数,模糊查询,都会影响索引的触发。
select * from emp where ename='SCOTT'
---复合索引
---创建复合索引
create index idx_enamejob on emp(ename, job);
---复合索引中第一列为优先检索列
---如果要触发复合索引,必须包含有优先检索列中的原始值。
select * from emp where ename='SCOTT' and job='xx';---触发复合索引
select * from emp where ename='SCOTT' or job='xx';---不触发索引
select * from emp where ename='SCOTT';---触发单列索引。
单列索引触发规则:条件必须是原始值,不能为模糊搜索或者聚合函数。
复合索引触发规则:第一列 (优先检索列) 必须为原始值。
6. pl/sql 编程语言
6.1 简介
pl/sql 编程语言是对 sql 语言的扩展,使得 sql 语言具有过程化编程的特性。
pl/sql 编程语言比一般的过程化编程语言,更加灵活高效。
pl/sql 编程语言主要用来编写存储过程和存储函数等。
---声明方法
---赋值操作可以使用:=也可以使用into查询语句赋值
declare
i number(2) := 10; ---number(2) 为类型
s varchar2(10) := '小明';
ena emp.ename%type; ---引用型变量
emprow emp%rowtype; ---记录型变量,类似于对象
begin
dbms_output.put_line(i); ---输出去语句
dbms_output.put_line(s);
select ename into ena from emp where empno = 7788;
dbms_output.put_line(ena);
select * into emprow from emp where empno = 7788;
dbms_output.put_line(emprow.ename || '的工作为:' || emprow.job); ---||连接输出
end;
6.2 if 判断
---输入小于18的数字,输出未成年
---输入大于18小于40的数字,输出中年人
---输入大于40的数字,输出老年人
declare
i number(3) := ⅈ --- &代表输入,ii 为变量,随便写
begin
if i<18 then
dbms_output.put_line('未成年');
elsif i<40 then
dbms_output.put_line('中年人');
else
dbms_output.put_line('老年人');
end if;
end;
6.3 循环
while 循环
---while循环
declare
i number(2) := 1;
begin
while i<11 loop
dbms_output.put_line(i);
i := i+1;
end loop;
end;
exit 结束循环
---exit循环
declare
i number(2) := 1;
begin
loop
exit when i>10;
dbms_output.put_line(i);
i := i+1;
end loop;
end;
for 循环
---for循环
declare
begin
for i in 1..10 loop
dbms_output.put_line(i);
end loop;
end;
6.4 游标
游标:可以存放多个对象,多行记录。
---输出emp表中所有员工的姓名
declare
cursor c1 is select * from emp;
emprow emp%rowtype;
begin
open c1;
loop
fetch c1 into emprow;
exit when c1%notfound;
dbms_output.put_line(emprow.ename);
end loop;
close c1;
end;
-----给指定部门员工涨工资
declare
cursor c2(eno emp.deptno%type)
is select empno from emp where deptno = eno;
en emp.empno%type;
begin
open c2(10);
loop
fetch c2 into en;
exit when c2%notfound;
update emp set sal=sal+100 where empno=en;
commit;
end loop;
close c2;
end;
----查询10号部门员工信息
select * from emp where deptno = 10;
7. 存储过程
存储过程就是提前已经编译好的一段 pl/sql 语言,放置在数据库端,可以直接被调用。这一段 pl/sql 一般都是固定步骤的业务。
创建存储过程的语法,in/out 代表参数是输入类型参数还是输出类型参数,参数默认 in
create [or replace] PROCEDURE 过程名[(参数名 in/out 数据类型)]
AS -- 或者 is
begin
PLSQL 子程序体;
End;
----给指定员工涨100块钱
create or replace procedure p1(eno emp.empno%type)
is
begin
update emp set sal=sal+100 where empno = eno;
commit;
end;
select * from emp where empno = 7788;
----测试p1
declare
begin
p1(7788);
end;
in 和 out 类型参数
---out类型参数如何使用
---使用存储过程来算年薪
create or replace procedure p_yearsal(eno emp.empno%type, yearsal out number)
is
s number(10);
c emp.comm%type;
begin
select sal*12, nvl(comm, 0) into s, c from emp where empno = eno;
yearsal := s+c;
end;
---测试p_yearsal
declare
yearsal number(10);
begin
p_yearsal(7788, yearsal);
dbms_output.put_line(yearsal);
end;
in 和 out 类型参数的区别是什么?
凡是涉及到 into 查询语句赋值或者 := 赋值操作的参数,都必须使用 out 来修饰。
8. 存储函数
存储过程和存储函数的区别?
一般来讲,过程和函数的区别在于函数可以有一个返回值;而过程没有返回值。
但过程和函数都可以通过 out 指定一个或多个输出参数。我们可以利用 out 参数,在过程和函数中实现返回多个值。
创建存储函数语法
create or replace function 函数名(Name in type, Name in type, ...) return 数据类型
is
结果变量 数据类型;
begin
return(结果变量);
end;
存储过程和存储函数的参数都不能带长度
存储函数的返回值类型不能带长度
----通过存储函数实现计算指定员工的年薪
----存储过程和存储函数的参数都不能带长度
----存储函数的返回值类型不能带长度
create or replace function f_yearsal(eno emp.empno%type) return number
is
s number(10);
begin
select sal*12+nvl(comm, 0) into s from emp where empno = eno;
return s;
end;
9. 触发器
触发器类型:
- 语句级触发器 :在指定的操作语句操作之前或之后执行一次,不管这条语句影响了多少行 。
- 行级触发器 (FOR EACH ROW) :触发语句作用的每一条记录都被触发。在行级触发器中使用 old 和 new 伪记录变量, 识别值的状态。
语法
CREATE [or REPLACE] TRIGGER 触发器名
{BEFORE | AFTER}
{DELETE | INSERT | UPDATE [OF 列名]}
ON 表名
[FOR EACH ROW [WHEN(条件) ] ]
begin
PLSQL 块
End 触发器名
语句级触发器
----插入一条记录,输出一个新员工入职
create or replace trigger t1
after
insert
on person
declare
begin
dbms_output.put_line('一个新员工入职');
end;
---触发t1
insert into person values (1, '小红');
commit;
select * from person;
行级别触发器
---不能给员工降薪
---raise_application_error(-20001~-20999之间, '错误提示信息');
create or replace trigger t2
before
update
on emp
for each row
declare
begin
if :old.sal>:new.sal then
raise_application_error(-20001, '不能给员工降薪');
end if;
end;
----触发t2
select * from emp where empno = 7788;
update emp set sal=sal-1 where empno = 7788;
commit;
触发器实现主键自增
----触发器实现主键自增。【行级触发器】
---分析:在用户做插入操作的之前,拿到即将插入的数据,
------给该数据中的主键列赋值。
create or replace trigger auid
before
insert
on person
for each row
declare
begin
select s_person.nextval into :new.pid from dual;
end;
--查询person表数据
select * from person;
---使用auid实现主键自增
insert into person (pname) values ('a');
commit;
insert into person values (1, 'b');
commit;