
19.【File 类、递归】
java.io.File类是文件和目录路径名的抽象表示,主要用于文件和目录的创建、查找和删除等操作。File类中的静态变量:系统分隔符static String pathSeparator:与系统有关的路径分隔符,Windows 为;,Linux 为:static public char pathSeparatorChar:与系统有关的路径分隔符static String separator:与系统有关的默认名称分隔符,Windows 为\,Linux 为/static char separatorChar:有系统有关的默认名称分隔符
File的构造方法:File(String pathname):将给定路径名字符串转换为抽象路径名来创建一个新File实例。String pathname:字符串的路径名称- 路径可以是文件结尾,也可以是文件夹结尾
- 路径可以是存在,也可以是不存在
- 创建
File对象,只是把字符串路径封装为File对象,不考虑路径真假情况
File(String parent,String child):根据parent路径名字符串和child路径名字符串创建一个新File实例。File(File parent,String child):根据parent抽象路径名和child路径名创建一个新的File实例。
File类的常用方法:public String getAbsolutePath():返回此File的绝对路径名字字符串。public String getPath():将此File转换为路径名字符串,根据创建的时候的相对或绝对,返回对应的路径。public String getName():返回由此File表示的文件或目录的名称。public long length():返回由此File表示的文件的长度,以字节为单位,路径为假,则返回 0。public boolean exists():返回文件或目录是否真实存在。public boolean isDirectory:是否是目录public boolean isFile():是否是文件- 路径不存在,返回
false。
- 路径不存在,返回
public boolean createNewFile():当且仅当目录不存在的时候,创建一个新的空文件。- 创建文件的路径和文件名在
File构造方法中给出。 - 创建成功返回
true,若文件存在,不会创建,返回false。 - 只能创建文件,不能创建文件夹。
- 若创建文件的路径不存在,则抛出异常。
- 创建文件的路径和文件名在
public boolean delete():删除此File表示的文件或目录。- 文件夹中有内容,不会删除,返回 false。
- 构造方法中路径不存在,返回 false。
- 直接在硬盘删除,不走回收站。
public boolean mkdir():创建由此File表示的目录。- 构造方法中给出的文件夹所在的路径不存在,返回 false,不会抛出异常。
- 当所创建的文件夹和文件重名时,即文件没有后缀名且和文件夹名字一样时,也返回
false。
public boolean mkdirs():创建由此File表示的目录,包括任何必须但不存在的父目录。public String[] list():表示File目录中的所有子文件或目录。public File[] listFiles():表示File目录中的所有子文件或目录。- 构造方法中给出的目录路径不存在或者不是目录,都会抛出空指针异常。
- 构造方法,禁止递归,编译报错。
java.io.FileFilter接口:File对象的过滤器,抽象方法boolean accept(File pathname)测试指定File对象是否应该包含在某个路径列表中。File pathname:使用ListFiles方法遍历目录,得到的每一个文件对象。
File类中重载方法public File[] listFiles(FileFilter filter):将File对象目录中符合过滤器条件的文件或目录返回。例子:package package1; import java.io.File; public class Main { public static void main(String[] args) { File list = new File("C:\\Users\\10766\\Desktop"); File[] files = list.listFiles(pathname -> pathname.getName().endsWith(".pdf")); //File[] files = list.listFiles(new FileFilter() { // @Override // public boolean accept(File pathname) { // if (pathname.getName().endsWith(".pdf")) { // return true; // } else { // return false; // } // } //}); for (File file1 : files) { System.out.println(file1); } } }java.io.FilenameFilter:实现此接口的类实例可用于过滤器文件名。- 抽象方法:
boolean accept(File dir, String name)测试指定文件是否应该包含在某一文件列表中。File dir:File的构造方法中传递的被遍历的目录String name:使用listFiles方法遍历目录,获取的每一个文件/文件夹的名称
- 抽象方法:
File中的重载方法File[] listFiles(FilenameFilter filter):将File对象目录中符合过滤器条件的文件或目录返回。例子:package package1; import java.io.File; import java.io.FilenameFilter; public class Main { public static void main(String[] args) { File list = new File("C:\\Users\\10766\\Desktop"); //过滤pdf和文件夹 File[] files = list.listFiles(new FilenameFilter() { @Override public boolean accept(File dir, String name) { return new File(dir, name).isDirectory() || name.toLowerCase().endsWith(".pdf"); } }); //File[] files = list.listFiles((dir, name) -> new File(dir, name).isDirectory() || name.toLowerCase().endsWith(".pdf")); for (File file1 : files) { System.out.println(file1); } } }
20.【字节流、字符流】
-
IO 流最顶层的父类(抽象类):
输入流 输出流 字节流 字节输入流** InputStream**字节输出流** OutputStream**字符流 字符输入流** Reader**字符输出流** Writer** -
字节流适合读取字节文件(图像等),字符流适合读取字符文件(txt)等。
-
java.io.OutputStream方法:-
public void close():关闭此输出流并释放与此流相关联的任何系统资源。 -
public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。 -
public void write(byte[] b):将b.length字节从指定的字节数组写入此输出流。- 如果写的第一个字节是正数(0-127),那么显示的时候会查询 ASCII 表。
- 如果写的第一个字节是负数,那第一个字节会和第二个字节,两个字节组成一个中文显示,查询系统默认码表(GBK)。
import java.io.FileOutputStream; import java.io.IOException; public class Demo01OutputStream { public static void main(String[] args) throws IOException { FileOutputStream fos = new FileOutputStream("C:\\Users\\10766\\Desktop\\a.txt"); byte[] bytes = {-65, -66, -67, 68, 69};//烤紻E fos.write(bytes); fos.close(); } }
-
public void write(byte[] b,int off,int len):将指定字节数组写入len字节,从偏移量off开始输出到此输出流。 -
public abstract void write(int b):将指定的字节输出流。- 要写入的字节是参数 b 的八个低位,b 的 24 个高位将被忽略。
-
-
java.io.FileOutputStream extends OutputStream:字节文件输出流,把内存中的数据写入到硬盘文件中。FileOutputStream(String name)创建一个向指定名称的文件中写入数据的输出文件流。FileOutputStream(String name, boolean qppend)创建一个向指定名称的文件中写入数据的输出文件流。FileOutputStream(File file)创建一个向指定File对象表示的文件中写入数据的文件输出流。FileOutputStream(File file, boolean append)创建一个向指定File对象表示的文件中写入数据的文件输出流。- 构造方法的作用:
- 创建一个对象
- 根据构造方法中传入的文件/文件路径,创建一个空的文件
- 把
FileOutputStream对象指向创建好的文件
-
import java.io.FileOutputStream; import java.io.IOException; public class Demo01OutputStream { public static void main(String[] args) throws IOException { //1.创建一个FileOutputStream对象,构造方法中传递写入数据的目的地 FileOutputStream fos = new FileOutputStream("C:\\Users\\10766\\Desktop\\a.txt"); //2.调用FileOutputStream对象中的方法write,把数据写入到文件中 //public abstract void write(int b) :将指定的字节输出流。 fos.write(97); //3.释放资源(流使用会占用一定的内存,使用完毕要把内存清空,提供程序的效率) fos.close(); } }
-
流使用会占用一定的内存,使用完毕要把内存清空,提升程序的效率。
-
字节输出流向硬盘写数据的时候的原理:
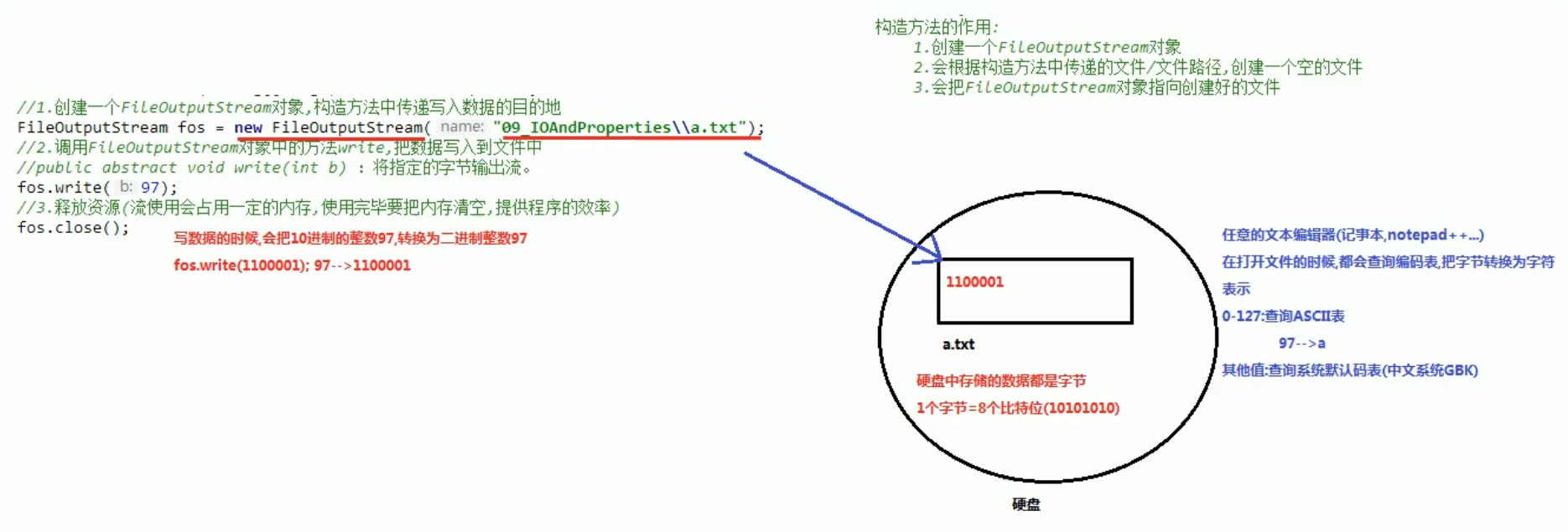
-
windows换行符为\r\n,Linix为\n,mac为\r。 -
java.io.InputStream:字节输入流int read()从输入流中读取数据的下一个字节,指针自动后移,读取到文件末尾返回-1。int read(byte[] b)从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。- 返回值为读取的有效字节个数,没有读到数据返回-1。
- b 的长度为每次最多读取的字节数,长度一般定义为 1024(1kb),或者 1024 的整数倍。
void close()关闭此输入流并释放与该流关联的所有系统资源。
-
java.io.FileInputStream extends InputStream:文件字节输入流,把硬盘中的数据,读取到内存中使用。FileInputStream(String name)FileInputStream(File file)参数为要读取的文件- 构造方法的作用:
- 会创建一个
FileInputStream对象 - 会把
FileInputStream对象指向构造方法中要读取的文件
- 会创建一个
-
读取数据文件的原理(硬盘 →内存):
Java 程序 →JVM→OS→OS 读取数据的方法 →读取文件
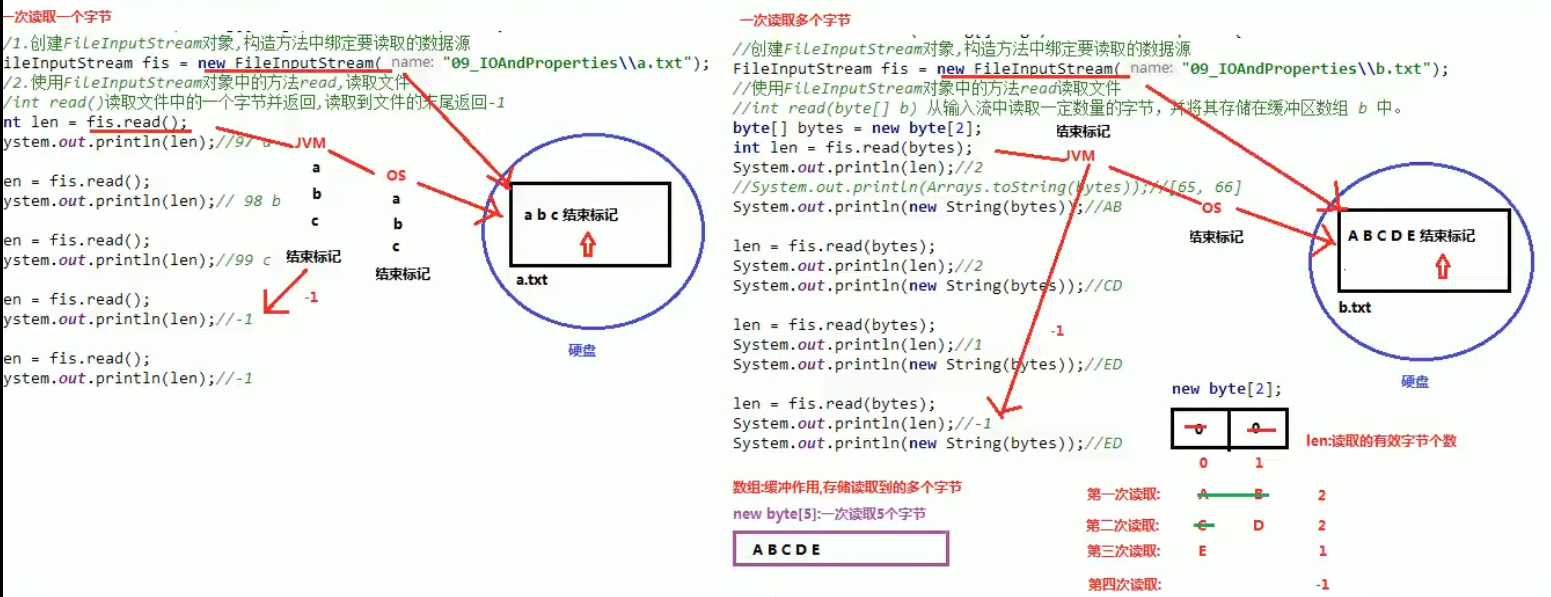
-
读取字节文件的样例:
package package1; import java.io.FileInputStream; import java.io.IOException; public class Main { public static void main(String[] args) throws IOException { FileInputStream fis = new FileInputStream("C:\\Users\\10766\\Desktop\\a.txt"); byte[] bytes = new byte[1024];//存储读取到的多个字节 int len = 0; //记录读取到的字节 while ((len = fis.read(bytes)) != -1) { //String(byte[] bytes, int offset, int length) 把字节数组的一部分转换为字符串 offset:数组的开始索引 length:转换的字节个数 String s = new String(bytes, 0, len); System.out.println(s); } //3.释放资源 fis.close(); } } -
关闭流的时候,先关闭输出流,再关闭输入流。
-
复制文件的例子:
package package1; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; public class Main { public static void main(String[] args) throws IOException { FileInputStream fis = new FileInputStream("C:\\Users\\10766\\Desktop\\a.txt"); FileOutputStream fos = new FileOutputStream("C:\\Users\\10766\\Desktop\\b.txt", true); byte[] bytes = new byte[1024]; int len = 0; while ((len = fis.read(bytes)) != -1) { fos.write(bytes, 0, len); } fos.close(); fis.close(); } } -
字符流每次读取一个字符,不管此字符占几个字节,例如中文在 GBK 占两个字节,在 UTF-8 占用三个字节。
-
java.io.Reader:字符输入流最顶层的父类,是一个抽象类。int read()读取单个字符并返回。len为读取到的字符,包含中文。
int read(char[] cbuf)一次读取多个字符,将字符读入数组。len为读取到的有效字符个数。
void close()关闭该流并释放与之关联的所有资源。
-
java.io.FileReader extends InputStreamReader extends Reader:文件字符输入流,把硬盘文件中的数据以字符的方式读取到内存中。FileReader(String filename)FileReader(File file)
-
FileReader的用法:import java.io.FileReader; import java.io.IOException; /* 字符输入流的使用步骤: 1.创建FileReader对象,构造方法中绑定要读取的数据源 2.使用FileReader对象中的方法read读取文件 3.释放资源 */ public class Demo02Reader { public static void main(String[] args) throws IOException { //1.创建FileReader对象,构造方法中绑定要读取的数据源 FileReader fr = new FileReader("09_IOAndProperties\\c.txt"); //2.使用FileReader对象中的方法read读取文件 //int read() 读取单个字符并返回。 /*int len = 0; while((len = fr.read()) != -1){ System.out.print((char)len); }*/ //int read(char[] cbuf)一次读取多个字符,将字符读入数组。 char[] cs = new char[1024];//存储读取到的多个字符 int len = 0;//记录的是每次读取的有效字符个数 while ((len = fr.read(cs)) != -1) { /* String类的构造方法 String(char[] value) 把字符数组转换为字符串 String(char[] value, int offset, int count) 把字符数组的一部分转换为字符串 offset数组的开始索引 count转换的个数 */ System.out.println(new String(cs, 0, len)); } //3.释放资源 fr.close(); } } -
java.io.Writer:所有字符输出流的最顶层的父类,是一个抽象类。其实现类有FileWriter:FileWriter(File file)FileWriter(File file, boolean append)FileWriter(Stirng filename)FileWriter(Stirng filename, boolean append)
-
java.io.FileWriter extends OutputStreamWriter extends Writer:文件字符输出流。void write(int c):写入单个字符void write(char[] cbuf)写入字符数组abstract void write(char[] buf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。void write(String str)写入字符串void write(String str, int off, int len)写入字符串的某一部分,off字符串的开始索引,len写的字符个数。void flush()刷新该流的缓冲,把内存缓冲区中的数据,刷新到文件中。void close()关闭此流,但需要先刷新它。
-
字符输出流的使用步骤:
- 创建
FileWriter对象,构造方法中绑定要写入数据的目的地 - 使用
FileWriter中的方法write,把数据写入到内存缓冲区中(字符转换为字节的过程) - 使用
FileWriter中的方法flush,把内存缓冲区中的数据,刷新到文件中 - 释放资源(会先把内存缓冲区中的数据刷新到文件中)
不刷新的数据会在内存缓冲区,输出流被刷新或者被关闭才会写入到硬盘
- 创建
-
flush和close方法的区别flush:刷新缓冲区,使用户流对象可以继续使用。close:先刷新缓冲区,然后通知系统释放资源,流对象不可以再被使用。
-
JDK7 新特性:在 try 的后边可以增加一个(),在括号中可以定义流对象,那么这个流对象的作用域就在 try 中有效,try 中的代码执行完毕,会自动把流对象释放,不用写 finally。
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; /* 格式: try(定义流对象;定义流对象....){ 可能会产出异常的代码 }catch(异常类变量 变量名){ 异常的处理逻辑 } */ public class Demo02JDK7 { public static void main(String[] args) { try ( FileInputStream fis = new FileInputStream("c:\\1.jpg"); FileOutputStream fos = new FileOutputStream("d:\\1.jpg")) { int len = 0; while ((len = fis.read()) != -1) { fos.write(len); } } catch (IOException e) { System.out.println(e); } } } -
JDK9 新特性:try 的前边可以定义流对象,在 try 后边的()中可以直接引入流对象的名称(变量名),在 try 代码执行完毕之后,流对象也可以释放掉,不用写 finally。
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; /* 格式: A a = new A(); B b = new B(); try(a,b){ 可能会产出异常的代码 }catch(异常类变量 变量名){ 异常的处理逻辑 } */ public class Demo03JDK9 { public static void main(String[] args) throws IOException { FileInputStream fis = new FileInputStream("c:\\1.jpg"); FileOutputStream fos = new FileOutputStream("d:\\1.jpg"); try (fis; fos) { int len = 0; while ((len = fis.read()) != -1) { fos.write(len); } } catch (IOException e) { System.out.println(e); } } } -
java.util.Properties extends Hashtable<K,V> implements Map<K,V>:Properties类表示了一个持久的属性集。Properties可保存在流中或从流中加载Properties集合是唯一一个和 IO 流相结合的集合- 可以使用
store方法,把集合中的临时数据,持久化写入到硬盘中存储 - 可以使用
load方法,把硬盘中保存的文件(键值对),读取到集合中使用
- 可以使用
Properties集合是一个双列集合,key和value默认都是String,无法更改
-
Properties中常用方法:Object setProperty(String key, String value)调用Hashtable的方法put。String getProperty(String key)相当于Map集合中的get(key)方法。Set<String> stringPropertyNames()此方法相当于 Map 集合中的keySet方法。void store(OutputStream out, String comments)把集合中的临时数据,持久化写入到硬盘中存储void store(Writer writer, String comments)OutputStream out字节输出流,不能写中文,会乱码-
为什么会产生乱码?
-
答:
store(OutputStream out, String comments)源码public void store(OutputStream out, String comments) throws IOException { store0(new BufferedWriter(new OutputStreamWriter(out, "8859_1")), comments, true); }Properties中存储的为字符,字符需要编码为字节,编码就需要编码格式,store中传入字节输出流的时候,以8859_1编码来调用OutputStreamWriter进行编码,此编码集不支持中文,FileWriter则使用默认编码进行编码。
-
Writer writer字符输出流,可以写中文String comments注释,用来解释说明保存的文件是做什么用的,不能使用中文,默认Unicode编码,一般使用""空字符串,文本表现为#占一行,可以为null,文本表现为没有注释行。-
package package1; import java.io.FileWriter; import java.io.IOException; import java.util.Properties; public class Main { public static void main(String[] args) throws IOException { Properties properties = new Properties(); properties.setProperty("赵丽颖", "168"); properties.setProperty("杨幂", "22"); properties.store(new FileWriter("javase\\a.txt"),""); } }
void load(InputStream inStream)把硬盘中保存的文件(键值对),读取到集合中使用,不能读取中文void load(Reader reader)可以读取中文- 存储键值对的文件中,键与值默认的连接符号可以使用 =,空格(其他符号)
- 存储键值对的文件中,可以使用#进行注释,被注释的键值对不会再被读取
- 存储键值对的文件中,键与值默认都是字符串,不用再加引号
21.【缓冲流、转换流、序列化流、打印流】
- 缓冲流也叫高效流,是对 4 个基本的
FileXxx流的增强:- 字节缓冲流:
BufferedInputStream,BufferedOutputStream - 字符缓冲流:
BufferedReader,BufferedWriter - 缓冲流的原理:创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统 IO 次数,从而提高读写的效率
- 字节缓冲流:
java.io.BufferedOutputStream extends OutputStream:BufferedOutputStream(OutputStream out):创建一个新的缓冲输出流,将数据写入指定的底层输出流。BufferedOutputStream(OutputStream out, int size): 创建一个新的缓冲输出流,将具有指定缓冲区大小的数据写入指定的底层输出流。- 关闭的时候,关闭
BufferedOutputStream即可,会自己关闭OutputStream。 -
public class Demo01BufferedOutputStream { public static void main(String[] args) throws IOException { //1.创建FileOutputStream对象,构造方法中绑定要输出的目的地 FileOutputStream fos = new FileOutputStream("10_IO\\a.txt"); //2.创建BufferedOutputStream对象,构造方法中传递FileOutputStream对象对象,提高FileOutputStream对象效率 BufferedOutputStream bos = new BufferedOutputStream(fos); //3.使用BufferedOutputStream对象中的方法write,把数据写入到内部缓冲区中 bos.write("我把数据写入到内部缓冲区中".getBytes()); //4.使用BufferedOutputStream对象中的方法flush,把内部缓冲区中的数据,刷新到文件中 bos.flush(); //5.释放资源(会先调用flush方法刷新数据,第4部可以省略) bos.close(); } }
java.io.BufferedInputStream extends InputStream:BufferedInputStream(InputStream in):创建一个BufferedInputStream并保存其参数,即输入流in,以便将来使用。BufferedInputStream(InputStream in, int size): 创建具有指定缓存区大小的对象,并保存其参数,即输入流in,以便将来使用。- 使用步骤:
- 创建
FileInputStream对象,构造方法中绑定要读取的数据源 - 创建
BufferedInputStream对象,构造方法中传递FileInputStream对象,提高FileInputStrea对象的读取效率 - 使用
BufferedInputStream对象中的方法read,读取文件 - 释放资源
- 创建
java.io.BufferedWriter extends Writer:字符缓冲输出流BufferedWriter(Writwe out): 创建一个使用默认大小输出缓冲区的缓冲字符输出流。BufferedWriter(Writer out, int sz):创建一个使用给定大小输出缓冲区的新缓冲字符输出流。void newLine(): 写入一个行分隔符。会根据不同的操作系统,获取不同的行分隔符。
java.io.BufferReader extends Reader: 字符缓冲输入流。BufferedReader(Reader in)创建一个使用默认大小输入缓冲区的缓冲字符输入流。BufferedReader(Reader in, int sz): 创建一个使用指定大小缓冲区的缓冲字符输入流。String readLine(): 读取一个文本行,读入一行数据。通过下列字符之一即可认为某行已终止:换行\n、回车\r或回车后直接跟着换行\r\n。返回包含该行内容的字符串,不包含任何行终止符,如果已到达流末尾,则返回null。-
import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; public class Demo04BufferedReader { public static void main(String[] args) throws IOException { //1.创建字符缓冲输入流对象,构造方法中传递字符输入流 BufferedReader br = new BufferedReader(new FileReader("10_IO\\c.txt")); //2.使用字符缓冲输入流对象中的方法read/readLine读取文本 String line; while ((line = br.readLine()) != null) { System.out.println(line); } //3.释放资源 br.close(); } }
- 使用字符流去读取文件的时候,底层调用的是字节流读取的文件,然后字符流进行解码,解码成可以看懂的字符展示出来,例如
FileReader底层调用的为FileInputStream。 FileReader类使用的是 IDEA 中的默认编码(UTF-8),当读取非默认编码文件的时候,就会出现乱码问题。- 若要读取指定编码的文件,则需要使用转换流
InputStreamReader,写指定编码,则使用OutputStreamWriter。 - 转换流的原理:
java.io.OutputStreamWriter extends Writer:是字符流通向字节流的桥梁,可使用指定的编码,将要写入流中的字符编码为字节。OutputStreamWriter(OutputStream out): 创建使用默认字符编码的OutputStreamWriter。OutputStreamWriter(OutputStream out, String charsetName): 创建使用指定字符集的OutputStreamWriter。OutputStream out:字节输出流,可以用来写转换之后的字节到文件中。String charsetName:指定的编码表名称,不区分大小写。
-
package package1; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStreamWriter; public class Main { public static void main(String[] args) throws IOException { //1.创建OutputStreamWriter对象,构造方法中传递字节输出流和指定的编码表名称 //OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("10_IO\\utf_8.txt"),"utf-8"); OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("10_IO\\utf_8.txt"));//不指定默认使用UTF-8 //2.使用OutputStreamWriter对象中的方法write,把字符转换为字节存储缓冲区中(编码) osw.write("你好"); //3.使用OutputStreamWriter对象中的方法flush,把内存缓冲区中的字节刷新到文件中(使用字节流写字节的过程) osw.flush(); //4.释放资源 osw.close(); } } flush()方法就是使用字节流写字节的过程。
java.io.InputStreamReader extends Reader: 是字节流通向字符流的桥梁,它使用指定的charset读取字节并将其解码为字符。InputStreamReader(InputStream in): 创建一个使用默认字符集的InputStreamReader。InputStreamReader(InputStream in, String charsetName): 创建使用指定字符集的InputStreamReader。- 构造方法中指定的编码表名称要和文件的编码相同,否则会发生乱码。
java.io.ObjectOutputStream extends OutputStream对象的序列化流,把对象以流的方式写入到文件中保存。原理:
ObjectOutputStream中的方法:ObjectOutputStream(OutputStream out): 创建写入指定ObjectStream的ObjectOutputStream。void writeObject(Object obj): 将指定的对象写入ObjectOutputStream。
- 要进行序列化和反序列化的类,需要实现
java.io.Serializable,否则会抛出NotSerializableException。Serializable接口也叫标记型接口,其中并没有内容,只起标记作用。 - 序列化之后的文件为二进制文件,无法查看。
java.io.ObjectInputStream extends InputStream: 对象的反序列化流,把文件中保存的对象,以流的方式读取出来使用。- 使用前提:
- 类必须实现
Serializable接口 - 必须存在类对象的 Class 文件,否则会抛出
ClassNotFoundException
- 类必须实现
ObjectInputStream(InputStream in): 创建从指定InputStream读取的ObjectInputStream。Object readObject()从指定ObjectInputStream读取对象。-
import package1.Person; import java.io.FileInputStream; import java.io.IOException; import java.io.ObjectInputStream; public class Demo02ObjectInputStream { public static void main(String[] args) throws IOException, ClassNotFoundException { //1.创建ObjectInputStream对象,构造方法中传递字节输入流 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("10_IO\\person.txt")); //2.使用ObjectInputStream对象中的方法readObject读取保存对象的文件 Object o = ois.readObject(); //3.释放资源 ois.close(); //4.使用读取出来的对象(打印) System.out.println(o); Person p = (Person) o; System.out.println(p.getName() + p.getAge()); } }
- 使用前提:
- 被
static修饰的成员变量不能被序列化,序列化的都是对象,静态优先于对象加载进内存private static int age; oos.writeObjecy(new Person("小美女", 18)); Object o = ois.readObject(); Person{name = "小美女", age = 0}; transient关键字:瞬态关键字,被transient修饰的成员变量,不能被序列化private transient age; oos.writeObject(new Person("小美女", 18)); Object o = ois.readObject(); Person{name = "小美女", age = 0};InvaildClassException序列化冲突异常的原理及解决方法:
- 当想在同一个文件保存多个对象的时候,可以将对象存储到集合中,然后序列化集合。
java.io.PrintStream extends OutputStream: 打印流,为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。- 只负责数据的输出,不负责数据的读取。
- 与其他输出流不同,
PrintStream永远不会抛出IOException。 - 有特有的方法,
print,println - 如果使用继承自父类的
write方法写数据,那么查看数据的时候会查询编码表 97->a - 如果使用自己特有的方法
print/println方法写数据,写的数据原样输出 97->97 PrintStream(File file)输出的目的地是一个文件PrintStream(File file, String csn)第二个参数为指定的字符集PrintStream(OutputStream out)输出目的地是一个字节输出流PrintStream(String fileName)输出的目的地是一个文件路径PrintStream(String fileName, String csn)第二个参数为指定的字符集
System.out对象为PrintStream。System.setOut方法可以改变输出语句的目的地,改为参数中传递的打印流的目的地。static void setOut(PrintStream out)重新分配标准输出流-
import java.io.FileNotFoundException; import java.io.PrintStream; public class Demo02PrintStream { public static void main(String[] args) throws FileNotFoundException { System.out.println("我是在控制台输出"); PrintStream ps = new PrintStream("10_IO\\目的地是打印流.txt"); System.setOut(ps);//把输出语句的目的地改变为打印流的目的地 System.out.println("我在打印流的目的地中输出"); ps.close(); } }
22.【网络编程】
-
UDP :用户数据报协议(User Datagram Protocol),是面向无连接的协议,不管对方端服务是否启动,直接发,每个数据包限制在 64k 以内,传输快,耗资小,不可靠,容易丢失数据。
-
TCP : 传输控制协议 (Transmission Control Protocol),面向连接的,先建立连接,再发送数据,提供可靠无差错的数据传输。三次握手:
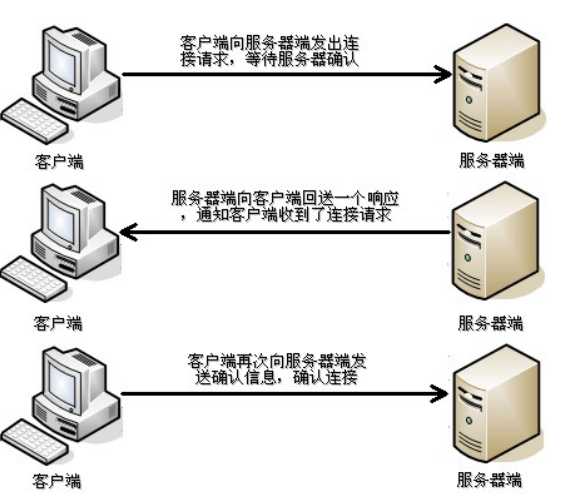
-
端口号由 2 个字节组成,范围为 0~65535 , 1024 之前的端口号已被系统分配,不能使用。
-
Oracle 默认端口号为 1521。
-
套接字是两台机器间通信的端点,包含了 IP 地址和端口号的网络单位。
-
TCP 通信的概述,服务器使用客户端的字节流与客户端进行交互,服务器端套接字
ServerSocket中方法Socket accept()可以获取到请求的客户端对象,但是此对象和客户端上面的Socket并非一个对象,因为不在一个机器上,自然不会指向同一个内存。
-
java.net.Socket类实现客户端的套接字。-
Socket(String host, int port)创建一个套接字,并将其连接到指定主机上的指定端口号。- 新建
Socket的时候,若无法连接至服务器,会抛出ConnectException异常。
- 新建
-
OutputStream getOutputStream()返回此套接字的输出流。 -
InputStream getInputStream()返回此套接字的输入流。 -
void close()关闭此套接字。 -
import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.net.Socket; public class TCPClient { public static void main(String[] args) throws IOException { //1.创建一个客户端对象Socket,构造方法绑定服务器的IP地址和端口号 Socket socket = new Socket("127.0.0.1", 8888); //2.使用Socket对象中的方法getOutputStream()获取网络字节输出流OutputStream对象 OutputStream os = socket.getOutputStream(); //3.使用网络字节输出流OutputStream对象中的方法write,给服务器发送数据 os.write("你好服务器".getBytes()); //4.使用Socket对象中的方法getInputStream()获取网络字节输入流InputStream对象 InputStream is = socket.getInputStream(); //5.使用网络字节输入流InputStream对象中的方法read,读取服务器回写的数据 byte[] bytes = new byte[1024]; int len = is.read(bytes); System.out.println(new String(bytes, 0, len)); //6.释放资源(Socket) socket.close(); } }
-
-
java.net.ServerSocket类实现服务器端套接字。ServerSocket(int port)创建绑定到指定端口的服务器套接字。Socket accept()监听并接受到此套接字的连接。-
import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.net.ServerSocket; import java.net.Socket; public class TCPServer { public static void main(String[] args) throws IOException { //1.创建服务器ServerSocket对象和系统要指定的端口号 ServerSocket server = new ServerSocket(8888); //2.使用ServerSocket对象中的方法accept,获取到请求的客户端对象Socket Socket socket = server.accept(); //3.使用Socket对象中的方法getInputStream()获取网络字节输入流InputStream对象 InputStream is = socket.getInputStream(); //4.使用网络字节输入流InputStream对象中的方法read,读取客户端发送的数据 byte[] bytes = new byte[1024]; int len = is.read(bytes); System.out.println(new String(bytes, 0, len)); //5.使用Socket对象中的方法getOutputStream()获取网络字节输出流OutputStream对象 OutputStream os = socket.getOutputStream(); //6.使用网络字节输出流OutputStream对象中的方法write,给客户端回写数据 os.write("收到谢谢".getBytes()); //7.释放资源(Socket,ServerSocket) socket.close(); server.close(); } }
-
Socket的OutputStream字节输出流中的read()方法,如果没有输入可用,则read将堵塞,读不到数据 的时候会堵塞,直到另一端发送终止序列或者将输出流关闭,可以调用socket.shutdownOutput()来半关闭Socket(只关闭输出流,不关闭输入流,也不会关闭连接)。void shutdownOutput()禁用此套接字的输出流。对于 TCP 套接字,任何以前写入的数据都将被发送,并且后跟 TCP 的正常连接终止序列。注意:当 read 阻塞的时候,另一端关掉 socket 就会关掉连接,此端的字节输出流自然也会被关闭。
-
socket.shutdownOutput()与outputStream.close()的区别,前者是半关闭,只关闭输出流,Scoket连接并不会被关闭,输出流半关闭以后,另一端输入流read会一直读入输出连接终止的信号,后者会关闭Socket连接。 -
文件上传案例:
package package1; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.net.Socket; /* 文件上传案例的客户端:读取本地文件,上传到服务器,读取服务器回写的数据 明确: 数据源:c:\\1.jpg 目的地:服务器 实现步骤: 1.创建一个本地字节输入流FileInputStream对象,构造方法中绑定要读取的数据源 2.创建一个客户端Socket对象,构造方法中绑定服务器的IP地址和端口号 3.使用Socket中的方法getOutputStream,获取网络字节输出流OutputStream对象 4.使用本地字节输入流FileInputStream对象中的方法read,读取本地文件 5.使用网络字节输出流OutputStream对象中的方法write,把读取到的文件上传到服务器 6.使用Socket中的方法getInputStream,获取网络字节输入流InputStream对象 7.使用网络字节输入流InputStream对象中的方法read读取服务回写的数据 8.释放资源(FileInputStream,Socket) */ public class TCPClient { public static void main(String[] args) throws IOException { //1.创建一个本地字节输入流FileInputStream对象,构造方法中绑定要读取的数据源 FileInputStream fis = new FileInputStream("d:\\1.jpg"); //2.创建一个客户端Socket对象,构造方法中绑定服务器的IP地址和端口号 Socket socket = new Socket("127.0.0.1", 8888); //3.使用Socket中的方法getOutputStream,获取网络字节输出流OutputStream对象 OutputStream os = socket.getOutputStream(); //4.使用本地字节输入流FileInputStream对象中的方法read,读取本地文件 int len = 0; byte[] bytes = new byte[1024]; while ((len = fis.read(bytes)) != -1) { //5.使用网络字节输出流OutputStream对象中的方法write,把读取到的文件上传到服务器 os.write(bytes, 0, len); } os.flush(); //此处write不会向服务器传结束标记,服务器read就会处于阻塞状态,服务器就不会向客户端回写数据,客户端的read也将被堵塞 /* 解决:上传完文件,给服务器写一个结束标记 void shutdownOutput() 禁用此套接字的输出流。 对于 TCP 套接字,任何以前写入的数据都将被发送,并且后跟 TCP 的正常连接终止序列。 */ socket.shutdownOutput(); //6.使用Socket中的方法getInputStream,获取网络字节输入流InputStream对象 InputStream is = socket.getInputStream(); //7.使用网络字节输入流InputStream对象中的方法read读取服务回写的数据 while ((len = is.read(bytes)) != -1) { System.out.println(new String(bytes, 0, len)); } //8.释放资源(FileInputStream,Socket) fis.close(); socket.close(); } }package package1; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.net.ServerSocket; import java.net.Socket; import java.util.Random; /* 文件上传案例服务器端:读取客户端上传的文件,保存到服务器的硬盘,给客户端回写"上传成功" 明确: 数据源:客户端上传的文件 目的地:服务器的硬盘 d:\\upload\\1.jpg 实现步骤: 1.创建一个服务器ServerSocket对象,和系统要指定的端口号 2.使用ServerSocket对象中的方法accept,获取到请求的客户端Socket对象 3.使用Socket对象中的方法getInputStream,获取到网络字节输入流InputStream对象 4.判断d:\\upload文件夹是否存在,不存在则创建 5.创建一个本地字节输出流FileOutputStream对象,构造方法中绑定要输出的目的地 6.使用网络字节输入流InputStream对象中的方法read,读取客户端上传的文件 7.使用本地字节输出流FileOutputStream对象中的方法write,把读取到的文件保存到服务器的硬盘上 8.使用Socket对象中的方法getOutputStream,获取到网络字节输出流OutputStream对象 9.使用网络字节输出流OutputStream对象中的方法write,给客户端回写"上传成功" 10.释放资源(FileOutputStream,Socket,ServerSocket) */ public class TCPServer { public static void main(String[] args) throws IOException { //1.创建一个服务器ServerSocket对象,和系统要指定的端口号 ServerSocket server = new ServerSocket(8888); //2.使用ServerSocket对象中的方法accept,获取到请求的客户端Socket对象 /* 让服务器一直处于监听状态(死循环accept方法) 有一个客户端上传文件,就保存一个文件 */ while (true) { Socket socket = server.accept(); /* 使用多线程技术,提高程序的效率 有一个客户端上传文件,就开启一个线程,完成文件的上传 */ new Thread(new Runnable() { //完成文件的上传 @Override public void run() { try { //3.使用Socket对象中的方法getInputStream,获取到网络字节输入流InputStream对象 InputStream is = socket.getInputStream(); //4.判断d:\\upload文件夹是否存在,不存在则创建 File file = new File("d:\\upload"); if (!file.exists()) { file.mkdirs(); } /* 自定义一个文件的命名规则:防止同名的文件被覆盖 规则:域名+毫秒值+随机数 */ String fileName = "itcast" + System.currentTimeMillis() + new Random().nextInt(999999) + ".jpg"; //5.创建一个本地字节输出流FileOutputStream对象,构造方法中绑定要输出的目的地 FileOutputStream fos = new FileOutputStream(new File(file, fileName)); //6.使用网络字节输入流InputStream对象中的方法read,读取客户端上传的文件 int len = 0; byte[] bytes = new byte[1024]; while ((len = is.read(bytes)) != -1) { //7.使用本地字节输出流FileOutputStream对象中的方法write,把读取到的文件保存到服务器的硬盘上 fos.write(bytes, 0, len); } fos.flush(); //8.使用Socket对象中的方法getOutputStream,获取到网络字节输出流OutputStream对象 //9.使用网络字节输出流OutputStream对象中的方法write,给客户端回写"上传成功" socket.getOutputStream().write("上传成功".getBytes()); //10.释放资源(FileOutputStream,Socket,ServerSocket) fos.close(); socket.close(); } catch (IOException e) { e.printStackTrace(); } } }).start(); } //服务器就不用关闭 //server.close(); } } -
模拟 B/S 服务器:

浏览器解析服务器回写的 HTML 页面,页面中如果有图片,浏览器就会单独的开启一个线程,读取服务器中的图片。package package1; import java.io.*; import java.net.ServerSocket; import java.net.Socket; /* 创建BS版本TCP服务器 */ public class TCPServer { public static void main(String[] args) throws IOException { //创建一个服务器ServerSocket,和系统要指定的端口号 ServerSocket server = new ServerSocket(8080); /* 浏览器解析服务器回写的html页面,页面中如果有图片,那么浏览器就会单独的开启一个线程,读取服务器的图片 我们就的让服务器一直处于监听状态,客户端请求一次,服务器就回写一次 */ while (true) { //使用accept方法获取到请求的客户端对象(浏览器) Socket socket = server.accept(); new Thread(new Runnable() { @Override public void run() { try { //使用Socket对象中的方法getInputStream,获取到网络字节输入流InputStream对象 InputStream is = socket.getInputStream(); //使用网络字节输入流InputStream对象中的方法read读取客户端的请求信息 /*byte[] bytes = new byte[1024]; int len = 0; while((len = is.read(bytes))!=-1){ System.out.println(new String(bytes,0,len)); }*/ //把is网络字节输入流对象,转换为字符缓冲输入流 BufferedReader br = new BufferedReader(new InputStreamReader(is)); //把客户端请求信息的第一行读取出来 GET /11_Net/web/index.html HTTP/1.1 String line = br.readLine(); System.out.println(line); //把读取的信息进行切割,只要中间部分 /11_Net/web/index.html String[] arr = line.split(" "); //把路径前边的/去掉,进行截取 11_Net/web/index.html String htmlpath = arr[1].substring(1); //创建一个本地字节输入流,构造方法中绑定要读取的html路径 FileInputStream fis = new FileInputStream(htmlpath); //使用Socket中的方法getOutputStream获取网络字节输出流OutputStream对象 OutputStream os = socket.getOutputStream(); // 写入HTTP协议响应头,固定写法 os.write("HTTP/1.1 200 OK\r\n".getBytes()); os.write("Content-Type:text/html\r\n".getBytes()); // 必须要写入空行,否则浏览器不解析 os.write("\r\n".getBytes()); //一读一写复制文件,把服务读取的html文件回写到客户端 int len = 0; byte[] bytes = new byte[1024]; while ((len = fis.read(bytes)) != -1) { os.write(bytes, 0, len); } //释放资源 fis.close(); socket.close(); } catch (IOException e) { e.printStackTrace(); } } }).start(); } //server.close(); } }
23.【函数式接口】
-
@FunctionalInterface函数式接口注解,编译器强制检查该接口是否是函数式接口。 -
Lambda 原理和匿名内部类不同,使用 Lambda 编译后不会产生
.class文件。 -
Lambda 使用前提:必须存在函数式接口;特点:延迟加载。延迟加载说明:
/* 日志案例 发现以下代码存在的一些性能浪费的问题 调用showLog方法,传递的第二个参数是一个拼接后的字符串 先把字符串拼接好,然后在调用showLog方法 showLog方法中如果传递的日志等级不是1级 就感觉字符串就白拼接了,存在了浪费 */ public class Demo01Logger { //定义一个根据日志的级别,显示日志信息的方法 public static void showLog(int level, String message) { if (level == 1) { System.out.println(message); } } public static void main(String[] args) { //定义三个日志信息 String msg1 = "Hello"; String msg2 = "World"; String msg3 = "Java"; //调用showLog方法,传递日志级别和日志信息 showLog(2, msg1 + msg2 + msg3); } }/* 使用Lambda优化日志案例 Lambda的特点:延迟加载 Lambda的使用前提,必须存在函数式接口 */ public class Demo02Lambda { //定义一个显示日志的方法,方法的参数传递日志的等级和MessageBuilder接口 public static void showLog(int level, MessageBuilder mb) { //对日志的等级进行判断,如果是1级,则调用MessageBuilder接口中的builderMessage方法 if (level == 1) { System.out.println(mb.builderMessage()); } } public static void main(String[] args) { //定义三个日志信息 String msg1 = "Hello"; String msg2 = "World"; String msg3 = "Java"; /* 使用Lambda表达式作为参数传递,仅仅是把参数传递到showLog方法中 只有满足条件,日志的等级是1级 才会调用接口MessageBuilder中的方法builderMessage 才会进行字符串的拼接 如果条件不满足,日志的等级不是1级 那么MessageBuilder接口中的方法builderMessage也不会执行 所以拼接字符串的代码也不会执行 所以不会存在性能的浪费 */ showLog(1, () -> { System.out.println("不满足条件不执行"); //返回一个拼接好的字符串 return msg1 + msg2 + msg3; }); } } -
函数是接口可以作为方法的返回值类型,此时可以返回一个 Lambda 表达式。
import java.util.Comparator; public class Main { public Comparator<String> getComparator() { return (o1, o2) -> o2.length() - o1.length(); } } -
JDK 提供了丰富的函数式接口,主要在
java.util.function包中。 -
函数式接口的使用方法一般都是:现有一个方法,在方法的参数中包含一个函数式接口,然后调用方法的时候,使用 Lambda 来实习这个函数式接口。
-
java.util.function.Supplier<T>被称为生产型接口,指定的泛型是什么类型,get方法就会生产什么类型的数据,接口仅包含一个无参方法:T get()用来获取一个指定类型的对象数据。-
package package1; import java.util.function.Supplier; public class Demo01Supplier { //定义一个方法,方法的参数传递Supplier<T>接口,泛型执行String,get方法就会返回一个String public static String getString(Supplier<String> sup) { return sup.get(); } public static void main(String[] args) { //调用getString方法,方法的参数Supplier是一个函数式接口,所以可以传递Lambda表达式 System.out.println(getString(() -> "胡歌")); } }
-
java.util.function.Consumer<T>接口为消费型接口,消费一个数据。void accept(T t)费一个指定泛型的数据。import java.util.function.Consumer; public class Main { public static void main(String[] args) { method("mi", name -> System.out.println(name)); } public static void method(String name, Consumer<String> con) { con.accept(name); } }default Consumer<T> andTher(Consumer<? super T> after)可以把两个 Consumer 接口组合到一起,在对数据进行消费,前面的先进行消费。-
import java.util.function.Consumer; public class Demo02AndThen { public static void method(String s, Consumer<String> con1, Consumer<String> con2) { //使用andThen方法,把两个Consumer接口连接到一起,在消费数据 con1.andThen(con2).accept(s);//con1连接con2,先执行con1消费数据,在执行con2消费数据 //等价于下面两行 //con1.accept(s); //con2.accept(s); } public static void main(String[] args) { method("Hello", (t) -> { System.out.println(t.toUpperCase()); }, (t) -> { System.out.println(t.toLowerCase()); }); } }
-
-
java.util.function.Predicate<T>接口,对某种数据类型的数据进行判断,结果返回一个boolean值。boolean test(T t)用来对指定数据类型数据进行判断的方法。-
import java.util.function.Predicate; public class Main { public static boolean method(String s, Predicate<String> p) { return p.test(s); } public static void main(String[] args) { boolean f = method("hello", s -> s.length() > 5); System.out.println(f); } }
-
default Predicate<T> and(Predicate<? super T> other)连接两个判断条件,都满足返回true。-
import java.util.function.Predicate; public class Main { public static void main(String[] args) { boolean f = method("hello", s -> s.length() == 5,s -> s.startsWith("h")); System.out.println(f); } public static boolean method(String s, Predicate<String> p1,Predicate<String> p2) { return p1.and(p2).test(s); } }
-
default Predicate<T> or(Predicate<? super T> other)连接两个判断条件,任何一个满足返回true。default Predicate<T> negate()对判定的结果取反。-
import java.util.function.Predicate; public class Main { public static void main(String[] args) { boolean f = method("hello", s -> s.length() == 5); System.out.println(f); } public static boolean method(String s, Predicate<String> p) { return p.negate().test(s); //等效于 //return !p.test(s); } }
-
-
java.util.function.Function<T,R>接口根据一个类型的数据得到另一个类型的数据。R apply(T t)根据类型 T 的参数获取类型 R 的结果。-
public class Main { public static void main(String[] args) { int ans = method("123", s -> Integer.parseInt(s)); System.out.println(ans); } public static int method(String s, Function<String,Integer> f) { return f.apply(s); } }
-
default <V> Function<T,V> andThen(Function<? super R,? extends V> after)用来进行组合操作,转换两次。-
import java.util.function.Function; public class Main { public static void main(String[] args) { int ans = method("123", s -> Integer.parseInt(s), integer -> integer + 100); System.out.println(ans);//223 } public static int method(String s, Function<String, Integer> f1, Function<Integer, Integer> f2) { return f1.andThen(f2).apply(s); //等效于 //Integer t = f1.appply(s); //return f2.apply(t); } }
-
24.【Stream流、方法引用】
-
Lambda 让我们更加专注于做什么,而不是怎么做。
-
Stream 流思想:
- Stream 流其实是一个集合元素的函数式模型(中间操作通过函数式接口实现),它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)。
- Stream 流是一个来自数据源的元素队列
- 元素是特定类型的对象,形成一个队列。 Java 中的 Stream 并不会存储元素,而是按需计算。
- 数据源(流的来源)。可以是集合、数组等。
- Stream 操作两个基础的特征:
- Pipelining(流水线): 中间操作都会返回流对象本身(原有的 Stream 对象不变,返回新对象)。这样多个操作可以串联成一个管道, 如同流式风格。这样做可以对操作进行优化,比如延迟执行和短路。
- 内部迭代: 以前对集合遍历都是通过
Iterator或者增强for的方式,显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式,流可以直接调用遍历方法。
- Stream 流并不会修改数据源。
- Stream 是延迟执行的,中间操作只是暂时保留,不会执行,遇到终止操作,才会执行,延迟执行来自于 Lambda 。
- Stream 流对象只可以使用一次。
-
java.util.stream.Stream<T>是 JDK8 新加入的接口,并非函数式接口。IntStream mapToInt(ToIntFunction<? super T> mapper)返回一个IntStream,其中包含将给定函数应用于此流的元素的结果。例如:mapToInt(Integer::intValue)。
-
java.util.stream.IntStream这是int原始专业Stream,适用于int,Stream只适用于对象 。Stream<Integer> boxed()返回一个Integer组成的Stream。
-
IntStream和Stream没有继承关系,有共同父类。 -
Stream 流的获取方式:
Collection集合:default Stream<E> stream()获取。Object数组:Stream 接口中静态方法static <T> Stream<T> of(T... values),获取流,参数可传递数组。- 基本类型数组:
static IntStream Arrays.stream(arr),不能使用Stream.of(T... values)获取,后者只适用于对象,整个数组会被当做一个对象,而前者返回IntStream适用于int类型。
-
Stream 流中的方法分为:
- 延迟方法:返回值类型仍是 Stream 接口自身类型的方法,因此支持链式调用。
- 终结方法:返回值类型不再是 Stream 接口自身类型的方法,因此不再支持链式调用,终结方法使用以后,就不能继续调用 Stream 流中别的方法,常见的有
count()和forEach()方法。
-
Stream 流中的常用方法:
-
Stream<T> filter(Predicate<? super T> predicate)用于对 Stream 流中的数据进行过滤。 -
Stream<R> map(Function<? super T, ? extends R> mapper)该接口需要一个Function函数式接口参数,可以将当前流中的 T 类型数据转换为另一种 R 类型的流。 -
long count()是一个终结方法,用于统计 Stream 流中元素的个数。 -
Stream<T> limit(long maxSize)对流进行截取,只取用前n个。 -
Stream<T> skip(long n)用于跳过元素,如果流的当前长度大于n,则跳过前n个,否则将会得到一个长度为0的空流。 -
Stream<T> sorted()返回由此流的元素组成的流,根据自然顺序排序。import java.util.stream.Stream; public class Main { public static void main(String[] args) { Stream<Integer> stream = Stream.of(1, -2, -3, 4, -5); stream.sorted().forEach(System.out::println); //-5,-3,-2,1,4 } } -
Stream<T> sorted(Comparator<? super T> comparator)返回由该流的元素组成的流,根据提供的 Comparator进行排序。 -
void forEach(Consumer<? super T> action)该方法接收一个Consumer接口函数(消费型接口),会将每一个流元素交给该函数进行处理。 -
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> n)合并两个流,得到一个新的流。 -
Object[] toArray()返回一个包含此流的元素的数组。 -
<A> A[] toArray(IntFunction<A[]> generator)变为数组,例如:toArray(String[]::new)。import java.util.stream.Stream; public class Main { public static void main(String[] args) { Stream<Integer> stream = Stream.of(1, -2, -3, 4, -5); Integer[] integers = stream.toArray(Integer[]::new); } } -
<R,A> R collect(Collector<? super T,A,R> collector): 通过此方法,可以将流转变为集合。-
此类中的参数
Collector为java.util.stream包下面的。 -
R 返回值即为要得到的集合,可以是
List、Map、Set等。 -
参数
Collector可通过java.util.stream.Collectors中的方法获取。-
toCollection(Supplier<C> collectionFactory)返回一个Collector,按照遇到的顺序将输入元素累加到一个新的Collection中。import java.util.ArrayList; import java.util.stream.Collectors; import java.util.stream.Stream; public class Main { public static void main(String[] args) throws Exception { Stream<Integer> stream = Stream.of(1, 2, 3); ArrayList<Integer> collect = stream.collect(Collectors.toCollection(ArrayList::new)); } } -
toList()返回一个 Collector ,它将输入元素List到一个新的List。import java.util.List; import java.util.stream.Collectors; import java.util.stream.Stream; public class Main { public static void main(String[] args) { Stream<Integer> stream = Stream.of(1, -2, -3, 4, -5); List<Integer> list = stream.collect(Collectors.toList()); } } -
toSet()返回一个 Collector ,将输入元素Set到一个新的Set。 -
toMap(Function<? super T,? extends K> keyMapper, Function<? super T,? extends U> valueMapper)返回一个Collector,它将元素累加到一个Map,其键和值是将所提供的映射函数应用于输入元素的结果。import java.util.Map; import java.util.stream.Collectors; import java.util.stream.Stream; public class Main { public static void main(String[] args) { Stream<String> stream = Stream.of("张三", "李四", "王五"); Map<String, String> map = stream.collect(Collectors.toMap(o -> o, s -> s + "的value")); System.out.println(map); //{李四=李四的value, 张三=张三的value, 王五=王五的value} } }
-
-
-
<R> R collect(Supplier<R> supplier, BiConsumer<R,? super T> accumulator, BiConsumer<R,R> combiner):通过此方法,可以将流转化为集合。- supplier:集合的构造函数
- accumulator:一个函数,可以向集合中添加一个元素
- combiner:可以组合两个集合的函数
-
// 以下将会将字符串累加到一个ArrayList : List<String> asList = stringStream.collect(ArrayList::new, ArrayList::add, ArrayList::addAll); // 以下将使用一串字符串并将它们连接成一个字符串: String concat = stringStream.collect(StringBuilder::new, StringBuilder::append, StringBuilder::append) .toString();
-
-
方法引用:符号:
::,例如(System.out::println),参数类型是可推导可省略的。-
@FunctionalInterface public interface MyInterface { void print(String name); }public class Main { public static void main(String[] args) { printMethod("hello", System.out::println); } public static void printMethod(String s, MyInterface p) { p.print(s); } }
-
-
Lambda 中传递的参数,一定是方法引用中引用的方法可以接收的类型,否则会抛异常。
-
类的构造器的引用:
类名称::new。 -
数组的构造器引用:
T[]::new。
25.【基础加强、反射、注解】
-
测试规范:
- 类名:被测试的类名 Test
- 包名:xxx.xxx.test,和要测试的包中的类平级
- 方法名:test 测试的方法名
- 返回值:void(不返回)
- 参数:空参(不调用)
- 注解:@Test
-
Junit 中
Assert.assertEquals(o1,o2)判断两个参数是否相等。o1 为期望值,o2 为要判断的值。 -
@Before 注解所有测试方法执行之前都会执行该方法,常用于资源申请。
-
@After 注解,所有测试方法执行完后,都会自动执行该方法,常用于资源释放。
-
三个阶段:
- Java 代码在计算机中有 Source 源代码阶段、Class 类对象阶段、Runtime 运行时阶段三个阶段。
- 类加载器(ClassLoader) 将字节码文件(.class 文件) 加载进内存。
- Class 类用来描述所有字节码文件共同的特征和行为。有三部分比较重要的东西,成员变量(封装为 Field 对象),构造方法(封装为 Constructor 对象),成员方法(封装为 Method 对象),因为会有多个成员变量、构造方法、成员方法,所以用数组存储。
-
反射:将类的各个组成部分封装为其他对象。
- 可以在程序运行过程中,操作这些对象(比如 IDE 的自动提示功能,就是读取了 Method[])。
- 可以解耦,提高程序的可扩展性。
-
获取 Class 对象的三种方式(分别对应三个阶段):
Class.forName("全类名")将字节码文件加载进内存,返回 Class 对象,多用于配置文件,将类名定义在配置文件中。读取文件,加载类。类名.class通过类名的属性class获取,多用于参数的传递。对象.getClass()此方法定义在Object类中,多用于对象的获取字节码的方式。
-
同一个字节码文件(.class)在一次程序运行过程中,只会被加载一次,不论通过哪一种方式获取的 Class 对象都是同一个。
-
Class 对象功能:
- 获取成员变量
Field[] getFields()获取所有public修饰的成员变量。Field getField(String name)获取指定名称的public修饰的成员变量。Field[] getDeclaredFields()获取所有的成员变量,不考虑修饰符,反射可以在类的外面访问到类中私有的东西。Field getDeclaredField(String name)-
package package1; import java.lang.reflect.Field; class Person { public int a; public String s; protected String b; String c; private String d; } public class Main { public static void main(String[] args) { Class<Person> personClass = Person.class; for (Field field : personClass.getFields()) { //只获取public System.out.println(field); } //结果 //public int package1.Person.a //public java.lang.String package1.Person.s for (Field declaredField : personClass.getDeclaredFields()) { //获取所有 System.out.println(declaredField); } //public int package1.Person.a //public java.lang.String package1.Person.s //protected java.lang.String package1.Person.b //java.lang.String package1.Person.c //private java.lang.String package1.Person.d } }
- 获取构造方法
Constructor<?>[] getConstructors()获取public修饰的构造方法。Constructor<T> getConstructor(Class<?>... parameterTypes)传入不同参数,获取参数对象的构造器,如果第二个参数为null,则按空数组处理。Constructor<T> getDeclaredConstructor(Class<?>... parameterTypes)Constructor<?>[] getDeclaredConstructors()获取所有构造方法。
- 获取成员方法
Method[] getMethods()Method getMethod(String name, Class<?>... parameterTypes)第一个参数为方法名,第二个参数为方法的参数的 Class 文件,用于辨别方法重载,如果第二个参数为null,则按空数组处理。Method[] getDeclaredMethods()Method getDeclaredMethod(String name, Class<?>... parameterTypes)
String getName()获取该 Class 的全类名。String getSimpleName()获取该 Class 的简短类名。ClassLoader getClassLoader()获取该 Class 的类加载器。T newInstance()调用该类的空参构造,返回该类的一个对象。
- 获取成员变量
-
java.lang.reflect.Field常用方法:void set(Object obj, Object value)为对象的此 Field 设置值。Object get(Object obj)获取某对象的这个 Field 的值-
package package1; import java.lang.reflect.Field; class Person { public String name; } public class Main { public static void main(String[] args) throws Exception { Class<Person> personClass = Person.class;//得到class对象 Field name = personClass.getField("name");//得到name的Field对象 Person person = new Person();//新建对象 name.set(person, "test");//为对象person的变量name设置值 Object ans = name.get(person);//获取person对象中变量name的值 System.out.println(ans); } }
-
String getName()返回此Field对象表示的字段的名称setAccessible(true)暴力反射,使用私有的东西的时候,需要首先用此语句忽略访问权限修饰符,否则会抛出IllegalAccessException异常。此方法是Constructor,Field,Method的父类java.lang.reflect.AccessibleObject所具有的方法,三者都可以使用。package package1; import java.lang.reflect.Field; class Person { private String name; public Person(String name) { this.name = name; } } public class Main { public static void main(String[] args) throws Exception { Class<Person> personClass = Person.class;//得到class对象 Field name = personClass.getDeclaredField("name");//得到name的Field对象 Person person = new Person("test");//新建对象 name.setAccessible(true);//暴力反射 Object ans = name.get(person); System.out.println(ans); } }
-
java.lang.reflect.Constructor常用方法:T newInstance(Object... initargs)package package1; import java.lang.reflect.Constructor; class Person { private String name; public Person() { } public Person(String name) { this.name = name; } } public class Main { public static void main(String[] args) throws Exception { Class<Person> personClass = Person.class;//得到class对象 Constructor<Person> constructor = personClass.getConstructor(String.class); Person p1 = constructor.newInstance("小明"); //对于空参构造方法,为了化简操作,Class 提供 T newInstance()方法 Person p2 = personClass.newInstance(); //等价于 Person p3 = personClass.getConstructor().newInstance(); } }
-
java.lang.reflect.Method常用方法:Object invoke(Object obj, Object... args)执行方法String getName()获取方法名
-
java.lang.ClassLoader常用方法InputStream getResourceAsStream(String name)返回读取指定资源的输入流。
-
获取配置文件的四种方法的区别:
URL XXX.class.getResource("A.properties")从 XXX 类的包路径下面查找文件。URL XXX.class.getResource("/A.properties")从 XXX 类的根路径(classpath 路径,编译前的 src)下面查找文件。URL XXX.class.getResourceAsStream()同理URL XXX.class.getClassLoader().getResource("A.properties")从 XXX 类的根路径(classpath 路径,编译前的 src,ClassLoader 路径)下面查找文件,可以自己写包路径packageName/A.properties。URL XXX.class.getClassLoader().getResource("/")返回 null。URL XXX.class.getClassLoader().getResourceAsStream()同理。
-
框架类案例,修改配置文件,可以执行任意类的任意方法
package cn.itcast.reflect; import cn.itcast.domain.Person; import cn.itcast.domain.Student; import java.io.IOException; import java.io.InputStream; import java.lang.reflect.Method; import java.util.Properties; /** * 框架类 */ public class ReflectTest { public static void main(String[] args) throws Exception { //可以创建任意类的对象,可以执行任意方法 /* 配置文件:pro.properties className= methodName= */ /* 前提:不能改变该类的任何代码。可以创建任意类的对象,可以执行任意方法 */ //1.加载配置文件 //1.1创建Properties对象 Properties pro = new Properties(); //1.2加载配置文件,转换为一个集合 //1.2.1获取class目录下的配置文件 ClassLoader classLoader = ReflectTest.class.getClassLoader(); InputStream is = classLoader.getResourceAsStream("pro.properties"); pro.load(is); //2.获取配置文件中定义的数据 String className = pro.getProperty("className"); String methodName = pro.getProperty("methodName"); //3.加载该类进内存 Class cls = Class.forName(className); //4.创建对象 Object obj = cls.newInstance(); //5.获取方法对象 Method method = cls.getMethod(methodName); //6.执行方法 method.invoke(obj); } } -
注解作用分类
- 编写文档
- 代码分析,使用反射
- 编译检查
-
Java 中预定义的注解
@Override检测被该注解标注的方法是否继承自父类(接口)。@Deprecated表示已经过时,仍然可以使用。@SuppressWarnings压制警告,例如:@SuppressWarnings("all")。
-
cmd中反编译:javap -c Name.class。 -
注解的格式:
元注解 public @interface 注解名称 { 属性列表; } -
注解本质就是一个接口,默认继承
java.lang.annotation.Annotation接口(所有注解都要扩展的接口)。反编译代码:public interface MyAnno extends java.lang.annotation.Annotation { } -
枚举:用
enum修饰,说明该类型是一个枚举类型public enum MyEnum { RED,YELLOW,GREEN; } //使用 //MyEnum.RED -
注解的属性:接口中的抽象方法。
- 属性的返回值有以下类型(不能为
void):- 基本数据
- String
- 枚举
- 注解
- 以上类型的数组
-
public @interface MyAnno { int a(); String b(); MyEnum c(); Override d(); int[] e(); }
- 定义了注解的属性,在使用的时候必须给属性赋值(有默认值的话则可以不赋值)。
- 如果定义属性的时候,使用了
default关键字给属性默认初始化,则使用注解的时候,可以不进行属性的赋值。@interface MyAnno { int a(); String b() default ""; Override d(); } @MyAnno(a=5,d=@Override) public class Main { public static void main(String[] args) { } } - 如果只给一个属性赋值,并且属性的名称是
value的话,则value可以省略,直接定义值即可。@interface MyAnno { String value() default ""; String a() default ""; } @MyAnno("name") public class Main { public static void main(String[] args) { } } - 数组赋值时,值使用
{}包裹,如果数组中只有一个值,则{}可以省略。@interface MyAnno { String[] a() default ""; String[] value() default ""; } //@MyAnno(a = {"aaa"}) //@MyAnno(a = "aaa") //@MyAnno(value = {"aaa"}) //@MyAnno(value = "aaa") //@MyAnno("aaa") @MyAnno(value = "aaa",a = {"aaa","bbb"}) public class Main { public static void main(String[] args) { } }
- 如果定义属性的时候,使用了
- 属性的返回值有以下类型(不能为
-
元注解:用于描述注解的注解。
@Target:描述注解能够作用的位置。- 属性
ElementType[] value()(枚举类型)可取值:TYPE:可以作用于类上METHOD:可以作用于方法上FIELD:可以作用于成员变量上-
import java.lang.annotation.ElementType; import java.lang.annotation.Target; @Target({ElementType.TYPE,ElementType.METHOD}) public @interface MyAnno { }
- 属性
@Retention:描述注解被保留的阶段。- 属性
RetentionPolicy value()(枚举类型)可取值(对应 Java 代码的三个阶段):SOURCE:注解仅会保留在.java文件中。CLASS:注解会保留到.class字节码文件中。RUNTIME:注解会保留到.class字节码文件中,并被 JVM 读取到,自己写的注解一般使用这个。
- 属性
@Documented:描述注解会被抽取到 API 文档中。@Inherited:描述注解会被子类继承
-
在程序中解析注解:获取注解中定义的属性值。
-
获取注解定义的位置的对象(Class, Method, Field)
-
获取指定的注解
A getAnnotation(Class<A> annocationClass): 其实就是在内存中生成了一个该注解接口的子类实现对象。boolean isAnnotationPresent(Class<? extends Annotation> annotationClass)判断是否有指定注解。
-
调用注解中的抽象方法获取配置属性的值。(
注解对象.抽象方法名) -
package package1; import annotation.Pro; import java.lang.reflect.Method; /** * 框架类 */ @Pro(className = "package1.Demo", methodName = "show") public class ReflectTest { public static void main(String[] args) throws Exception { /* 前提:不能改变该类的任何代码。可以创建任意类的对象,可以执行任意方法 */ //1.解析注解 //1.1获取该类的字节码文件对象 Class<ReflectTest> reflectTestClass = ReflectTest.class; //2.获取上边的注解对象 //其实就是在内存中生成了一个该注解接口的子类实现对象 /* public class ProImpl implements Pro{ public String className(){ return "cn.itcast.annotation.Demo1"; } public String methodName(){ return "show"; } } */ Pro an = reflectTestClass.getAnnotation(Pro.class); //3.调用注解对象中定义的抽象方法,获取返回值 String className = an.className(); String methodName = an.methodName(); //System.out.println(className); //System.out.println(methodName); //3.加载该类进内存 Class cls = Class.forName(className); //4.创建对象 Object obj = cls.newInstance(); //5.获取方法对象 Method method = cls.getMethod(methodName); //6.执行方法 method.invoke(obj); } }package annotation; import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; /** * 描述需要执行的类名,和方法名 */ @Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) public @interface Pro { String className(); String methodName(); }
-
-
注解不是程序的一部分(没有注解照应运行),可以理解为就是一个标签。
-
注解给谁用:
- 编译器
- 给解析程序用
-
Java 使用反射机制调用方法的时候,捕获到的异常是
java.lang.reflect.InvocationTargetException是一种包装由调用方法或构造方法所抛出异常的经过检查的异常,此异常的message为null,我们若要获取真正的异常,应当使用Throwable getCause()方法来获取真正的异常。package package1; import java.lang.reflect.Method; public class TestCheck { public static void main(String[] args) throws NoSuchMethodException { Calculator c = new Calculator(); Class<? extends Calculator> cls = c.getClass(); Method add = null; add = cls.getMethod("div"); try { add.invoke(c); } catch (Exception e) { //此时必须加上getCause() System.out.println(e.getCause().getMessage()); } } }
26.【JDBC】
- 概念:Java DataBase Connectivity ,Java 数据库连接,Java 语言操作数据库。
- JDBC 本质:官方定义的一套操作所有关系型数据库的规则,即接口。各个数据库厂商去实现这套接口,提供数据库驱动 jar 包。我们可以使用这套接口(JDBC)编程,真正执行的代码是驱动 jar 包中的实现类。
- JDBC 的基本使用步骤(mysql)
package package1; import java.sql.Connection; import java.sql.DriverManager; import java.sql.Statement; /** * JDBC快速入门 */ public class JdbcDemo1 { public static void main(String[] args) throws Exception { //1. 导入驱动jar包 //2.注册驱动 Class.forName("com.mysql.jdbc.Driver"); //3.获取数据库连接对象 Connection conn = DriverManager.getConnection("jdbc:mysql:///db3", "root", "root"); //4.定义sql语句 String sql = "update account set balance = 2000"; //5.获取执行sql的对象 Statement Statement stmt = conn.createStatement(); //6.执行sql int count = stmt.executeUpdate(sql); //7.处理结果 System.out.println(count); //8.释放资源 stmt.close(); conn.close(); } } java.sql.DriverManager:JDBC 驱动管理对象。-
static void registerDriver(Driver driver)注册给定的驱动程序 -
Class.forName("com.mysql.jdbc.Driver")源码public Driver() throws SQLException { } static { try { DriverManager.registerDriver(new Driver()); } catch (SQLException var1) { throw new RuntimeException("Can't register driver!"); } }可见,调用了上面的方法,与上面方法的效果一样,为了方便,一般使用这种用法。
注意:mysql5 之后的驱动 jar 包可以省略注册驱动的步骤 -
static Connection getConnection(String url, String user, String password)获取数据库连接。- url 的语法:
协议名:子协议://IP地址:端口号/数据库名?参数1=参数2值&参数2=参数2值,所以一般写为jdbc:mysql://localhost:3306/数据库名,如果是本地服务器和 3306 端口的话,可以简写为jdbc:mysql:///数据库名。
- url 的语法:
-
- 事务:一个包含多个步骤的业务操作。如果这个业务操作被事务管理,则这个步骤要么同时成功,要么同时失败。事务操作使用
Connection中方法来管理。 java.sql.Connection数据库连接对象Statement createStatement()获取执行静态 SQL 语句的对象。PreparedStatement preparedStatement(String sql)获取执行预编译 SQL 语句的对象void setAutoCommit(boolean autocommit)参数设为 false ,开启事务,在执行 SQL 之前开启事务。void commit()提交事务,当所有 SQL 都执行完提交事务。void rollback()回滚事务,在catch中回滚事务。-
package package2; import util.JDBCUtils; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.SQLException; /** * 事务操作 */ public class JDBCDemo10 { public static void main(String[] args) { Connection conn = null; PreparedStatement pstmt1 = null; PreparedStatement pstmt2 = null; try { conn = JDBCUtils.getConnection(); //开启事务 conn.setAutoCommit(false); //定义sql 张三 - 500 String sql1 = "update account set balance = balance - ? where id = ?"; //李四 + 500 String sql2 = "update account set balance = balance + ? where id = ?"; //3.获取执行sql对象 pstmt1 = conn.prepareStatement(sql1); pstmt2 = conn.prepareStatement(sql2); //4. 设置参数 pstmt1.setDouble(1, 500); pstmt1.setInt(2, 1); pstmt2.setDouble(1, 500); pstmt2.setInt(2, 2); //5.执行sql pstmt1.executeUpdate(); // 手动制造异常 int i = 3 / 0; pstmt2.executeUpdate(); //提交事务 conn.commit(); } catch (Exception e) { //事务回滚 try { if (conn != null) { conn.rollback(); } } catch (SQLException e1) { e1.printStackTrace(); } e.printStackTrace(); } finally { JDBCUtils.close(pstmt1, conn); JDBCUtils.close(pstmt2, null); } } }
java.sql.Statement用于执行静态 SQL 语句并返回其生成的结果的对象。boolean execute(String sql):执行任意 SQL 语句,结果为 ResultSet 则返回 true,不常用,了解。int executeUpdate(String sql):执行 DML (insert、update、delete) 语句、DDL (create、alter、drop) 语句,很少使用 Java 执行 DDL 语句,返回值为影响的行数。ResultSet executeQuery(String sql):执行 DQL (select) 语句。- 存在 SQL 注入问题
- 输入密码:
a' or 'a' = 'a',SQL 语句就会变成select * from user where username = 'name' and password = 'a' or 'a' = 'a'
- 输入密码:
java.sql.PreparedStatement extends Statement: 执行预编译 SQL 语句的对象,防止 SQL 注入,效率更高。- SQL 语句使用
?作为占位符。 void setXxx(参数1, 参数2)参数 1 为?的编号(从 1 开始),参数 2 为?的值。PreparedStatement的executeXxxx()方法不需要传递参数,创建对象的时候已经传过 SQL 语句。
- SQL 语句使用
java.sql.ResultSet结果集对象,封装查询结果。boolean next()判断下一行是否有数据,有的话,返回 true 并把光标向下移动一行。Xxx getXxx(参数)获取数据。- Xxx:代表数据类型,如
int getInt(), String getString() - 参数,若是 int ,代表列的编号(从 1 开始),若是 String 代表列的名称。
getDate()返回值为java.sql.Date extends java.util.Date。
- Xxx:代表数据类型,如
- Java 中资源释放顺序一般遵循,先关输出,在关输入(OutputStream、InputStream);后开先关(Result、PrepareStatement、Connection),先外后内(BufferedInputStream、InputStream)规则。
- 捕获异常可以这样写
try { } catch (ClassNotFoundException | IOException e) { e.printStackTrace(); } - JDBCUtils 工具类:
package util; import java.io.FileReader; import java.net.URL; import java.sql.*; import java.util.Properties; /** * JDBC工具类 */ public class JDBCUtils { private static String url; private static String user; private static String password; private static String driver; /** * 文件的读取,只需要读取一次即可拿到这些值。使用静态代码块 */ static { //读取资源文件,获取值 try { //1. 创建Properties集合类。 Properties pro = new Properties(); //获取src路径下的文件的方式--->ClassLoader 类加载器 ClassLoader classLoader = JDBCUtils.class.getClassLoader(); URL res = classLoader.getResource("jdbc.properties"); String path = res.getPath(); //2. 加载文件 pro.load(new FileReader(path)); //3.获取数据,赋值 url = pro.getProperty("url"); user = pro.getProperty("user"); password = pro.getProperty("password"); driver = pro.getProperty("driver"); //4.注册驱动 Class.forName(driver); } catch (Exception e) { e.printStackTrace(); } } /** * 获取连接 * * @return 连接对象 */ public static Connection getConnection() { try { return DriverManager.getConnection(url, user, password); } catch (SQLException e) { e.printStackTrace(); } return null; } /** * @param url * @param user * @param password * @return * @throws SQLException */ public static Connection getConnection(String url, String user, String password) { try { return DriverManager.getConnection(url, user, password); } catch (SQLException e) { e.printStackTrace(); } return null; } /** * 释放资源 * * @param stmt * @param conn */ public static void close(Statement stmt, Connection conn) { if (stmt != null) { try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); } } if (conn != null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } /** * 释放资源 * * @param rs * @param stmt * @param conn */ public static void close(ResultSet rs, Statement stmt, Connection conn) { if (rs != null) { try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } close(stmt, conn); } }
27.【JDBC 连接池、JDBCTemplate】
-
java包是Java API标准的包,javax是扩展包,org是由企业或组织提供的 Java 类库。 -
数据库连接池的好处:
- 节约资源
- 用户访问高效
-
javax.sql.DataSource数据库连接池的标准接口,由数据库厂商提供Connection getConnection()获取连接Connection.close()归还连接,如果连接对象Connection是从连接池中获取的,那么调用Connection.close()方法,则不会再关闭连接了,而是归还连接。
-
C3P0 数据库连接池技术
- 导入 jar 包。
- 定义配置文件:名称必须为
c3p0.propertied或者c3p0-config.xml,将文件放置在 src 目录下即可(src 目录的东西编译的时候会全部放置到 class 类路径中)。 - 创建核心对象:数据库连接池对象
CombopooledDataSource。 - 获取连接:
getConnection。
import com.mchange.v2.c3p0.ComboPooledDataSource; import javax.sql.DataSource; import java.sql.Connection; import java.sql.SQLException; public class Main { public static void main(String[] args) throws SQLException { DataSource ds = new ComboPooledDataSource();//可通过传参获取指定name的配置,空参代表使用默认配置 Connection connection = ds.getConnection(); System.out.println(connection); } }配置文件样例:
<c3p0-config> <!-- 使用默认的配置读取连接池对象 --> <default-config> <!-- 连接参数 --> <property name="driverClass">com.mysql.jdbc.Driver</property> <property name="jdbcUrl">jdbc:mysql://localhost:3306/mysql</property> <property name="user">root</property> <property name="password">123456</property> <!-- 连接池参数 --> <property name="initialPoolSize">5</property> <!-- 最大可同时连接的数量--> <property name="maxPoolSize">10</property> <!-- 超时时间--> <property name="checkoutTimeout">3000</property> </default-config> <!-- 指定名称的配置 --> <named-config name="otherc3p0"> <!-- 连接参数 --> <property name="driverClass">com.mysql.jdbc.Driver</property> <property name="jdbcUrl">jdbc:mysql://localhost:3306/day25</property> <property name="user">root</property> <property name="password">123456</property> <!-- 连接池参数 --> <property name="initialPoolSize">5</property> <property name="maxPoolSize">8</property> <property name="checkoutTimeout">1000</property> </named-config> </c3p0-config> -
Druid:数据库连接池实现技术,由阿里巴巴提供
- 导入 jar 包。
- 定义配置文件:是 properties 形式的,可以叫任意名称,放在任意目录下。
- 加载配置文件
.properties。 - 获取数据库连接池对象:通过工厂类
DruidDataSourceFactory获取。 - 获取连接:
getConnection。
driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql:///test username=root password=123456 initialSize=5 # 最大连接数 maxActive=10 maxWait=3000package package1; import com.alibaba.druid.pool.DruidDataSourceFactory; import javax.sql.DataSource; import java.io.InputStream; import java.sql.Connection; import java.util.Properties; public class Main { public static void main(String[] args) throws Exception { Properties pro = new Properties(); InputStream resourceAsStream = Main.class.getClassLoader().getResourceAsStream("druid.properties"); pro.load(resourceAsStream); DataSource ds = DruidDataSourceFactory.createDataSource(pro); Connection conn = ds.getConnection(); System.out.println(conn); conn.close(); } } -
Druid-JDBCUtils
package utils; import com.alibaba.druid.pool.DruidDataSourceFactory; import javax.sql.DataSource; import java.io.IOException; import java.sql.Connection; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import java.util.Properties; /** * Druid连接池的工具类 */ public class JDBCUtils { //1.定义成员变量 DataSource private static DataSource ds; static { Properties pro = new Properties(); try { //1.加载配置文件 pro.load(JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties")); //2.获取DataSource ds = DruidDataSourceFactory.createDataSource(pro); } catch (IOException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } /** * 获取连接 */ public static Connection getConnection() throws SQLException { return ds.getConnection(); } /** * 释放资源 */ public static void close(Statement stmt, Connection conn) { close(null, stmt, conn); } public static void close(ResultSet rs, Statement stmt, Connection conn) { if (rs != null) { try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } if (stmt != null) { try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); } } if (conn != null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } /** * 获取连接池方法 */ public static DataSource getDataSource() { return ds; } } -
JdbcTemplate:Spring 框架对 JDBC 进行了封装,提供 JdbcTemplate 对象简化 JDBC 的开发。JdbcTemplate(DataSource dataSource):传递数据库连接池。int update(String sql):执行 DML 语句。增删改语句。int update(String sql, Object... args):args 为取代?的值,位置要对应。Map<String,Object> queryForMap(String sql, Object... args):查询结果并将结果集封装为 Map 集合,Key 为列名,Value 为值,此方法查询返回的长度只能为 1,重载方法没第二个参数。List<Map<String,Object>> queryForList(String sql, Object... args):查询结果并将结果集封装为 List 集合,重载方法没第二个参数。<T> List<T> query(String sql, RowMapper<T> rowMapper)将结果封装为 List ,List 中存的为 JavaBean 对象。<T> List<T> query(String sql, RowMapper<T> rowMapper, Object... args)<T> List<T> query(String sql, Object[] args, RowMapper<T> rowMapper)<T> T queryForObject(String sql, Class<T> requiredType, Object... args)查询结果,将结果封装为指定对象,一般用于聚合函数。
-
RowMapper<T>介绍:为接口,含有抽象方法T mapRow(ResultSet var1, int var2)- 通过实现此接口封装为 JavaBean 对象
package package1; import bean.User; import org.springframework.jdbc.core.JdbcTemplate; import org.springframework.jdbc.core.RowMapper; import utils.JDBCUtils; import java.sql.ResultSet; import java.sql.SQLException; import java.util.List; public class Main { public static void main(String[] args) throws Exception { JdbcTemplate template = new JdbcTemplate(JDBCUtils.getDataSource()); String sql = "select * from user where age = ?"; List<User> list = template.query(sql, new RowMapper<User>() { @Override public User mapRow(ResultSet resultSet, int i) throws SQLException { User user = new User(); int id = resultSet.getInt("id"); String username = resultSet.getString("username"); String password = resultSet.getString("password"); int age = resultSet.getInt("age"); user.setId(id); user.setUsername(username); user.setPassword(password); user.setAge(age); return user; } }, 18); for (User user : list) { System.out.println(user); } } } - 通过调用服务商实现的子类的构造方法
BeanPropertyRowMapper(Class<T> mappedClass)(一般这样使用),这样使用的时候 Bean 类中的字段和数据库表中的字段完全对应(字段名字一样或者类中驼峰式与数据库表中的下划线式对应)package package1; import bean.User; import org.springframework.jdbc.core.BeanPropertyRowMapper; import org.springframework.jdbc.core.JdbcTemplate; import utils.JDBCUtils; import java.util.List; public class Main { public static void main(String[] args) throws Exception { JdbcTemplate template = new JdbcTemplate(JDBCUtils.getDataSource()); String sql = "select * from user where age = ?"; List<User> list = template.query(sql, new BeanPropertyRowMapper<User>(User.class), 18); for (User user : list) { System.out.println(user); } } }
- 通过实现此接口封装为 JavaBean 对象
-
JdbcTemplate使用步骤- 导入 jar 包
- 创建 JdbcTemplate 对象,构造方法传递数据源 DataSource
- 调用 JdbcTemplate 的方法来完成 CRUD 的操作。